| 제목 | 엔비디아, 딥러닝 신경망추론(NNI) 위한 테슬라 2종 신규 발표 | 추천 | 0 | IP 주소 | 110.13.xxx.111 |
|---|---|---|---|---|---|
| 글쓴이 | 닥터몰라 | 날짜 | 2016.09.18 20:26 | 조회 수 | 4808 |
|
글쓴이 : 이대근 원문 : http://drmola.com/news/77217 ※ 이 글은 AnandTech의 기사(링크)를 초월번역해 재구성한 것입니다.
지난 몇달간 엔비디아는 자사의 GPU 라인업에 머리끝부터 발끝까지 차근차근 파스칼 아키텍처를 갈아입혀 왔다. 최고가 라인업인 테슬라는 다섯달 전 가장 먼저 파스칼을 적용해 탈바꿈한 바 있는데(링크), 오늘은 그보다 조금 저렴한 하위 라인업을 소개하게 되었다. 추석 연휴 하루 전날인 지난 13일, 베이징에서 열린 GPU 테크놀러지 컨퍼런스(GTC) 2016 키노트 스피치를 통해 엔비디아의 젠슨 황 CEO는 테슬라 P40과 P4의 두 가지 모델을 신규 발표했다. 이들 모두 근래 엔비디아의 가장 큰 관심사인 딥러닝에 최적화되어 있으며 이들을 통해 신경망추론(NNI, Neural Network Inference) 분야가 목말라하는 가격대 성능비의 솔루션을 제공할 수 있게 되었다고 엔비디아는 전했다.
GPU 제조사인 엔비디아가 딥러닝에 천착하는 것은 전혀 놀라울 일이 아니다. 현재 컴퓨팅 시장 전체를 통틀어 가장 빠르게 성장하는 분야이기도 하며 이 분야가 요구하는 연산성능을 구현하는 데 GPU 아키텍처가 대단히 효율적이기 때문이다. 지속적으로 수 세대에 걸쳐 이러한 흐름이 누적된 끝에 파스칼은 개발 단계에서부터 신경망추론에의 최적화를 공언하기에 이르렀고, 이는 수많은 연산항목 가운데에서도 그간 주목받지 못하던 저정밀도 분야에서의 개선으로 이어졌다. 전세대의 맥스웰 역시 딥러닝 분야에서 꽤 쓸만한 성능을 보였지만 파스칼은 전혀 다른 클래스의 성능을 갖추게 된 것.
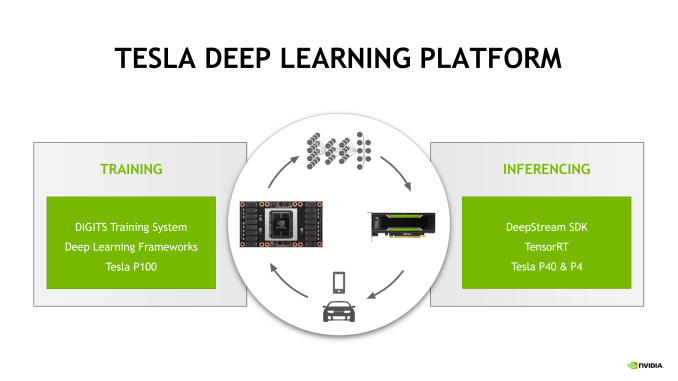
딥러닝 시장을 위한 엔비디아의 제품 라인업은 크게 두 부류로 구분되어 있다. 첫번째로 신경망훈련(NNT, Neural Network Training)에 최적화된 것들이다. 이들은 저정밀도 연산분야 가운데서도 반정밀도 부동소수점(FP16) 연산성능이 중시되며 대단히 많은 연산량을 처리해야 하는 것이 특징으로, 이를 겨냥한 제품으로는 테슬라 P100이 있다. 반면 다른 하나의 카테고리인 신경망추론의 경우 그보다는 연산량과 정밀도 모두 요구되는 수준이 다소 낮다. 이전까지는 이 시장을 겨냥해 테슬라 M40과 M4의 두 가지 모델이 존재했는데 오늘의 발표로써 이들 모두 파스칼이라는 새 옷을 입게 되었다. 머릿글자가 P로 바뀌었음은 물론이다.
대체로 테슬라 P40과 P4는 그들의 전임자들을 “닮았다”. 폼팩터 자체가 거의 유사하단 얘기다. 뿐만 아니라 TDP도 동일한 수준이며 가격마저도 거의 같아 시장에는 어떤 혼란도 초래하지 않을 것이다. 단 하나 달라진 게 있다면 아키텍처가 맥스웰에서 파스칼로 교체되었다는 것뿐.
앞서 언급했듯 ‘추론’ 자체는 그리 높은 정밀도의 연산을 요구하지 않는다. 전세대의 맥스웰 기반 제품들은 단정밀도 부동소수점(FP32) 연산성능을 활용했는데 이마저도 불필요하리만치 높은 제원이었다. 따라서 엔비디아는 GP100에 2배속 반정밀도 부동소수점(FP16) 연산을 도입한 데 이어, 여전히 정밀도가 남아 돈다고 생각했는지 GP102와 GP104에는 2배속 FP16 대신 4배속 8비트 정수(INT8) 연산으로까지 후려치기에 이른다. 이러한 고려 끝에 탄생한 GP102와 GP104의 FP32 연산유닛은 사이클당 하나의 FP32 명령어뿐 아니라 사이클당 4개의 INT8 명령어를 처리할 수 있다. 맥스웰까지는 없던 기능이다. 이러한 병렬성 개선에 더해 작동 속도 역시 큰 폭으로 상향되면서 파스칼은 전례없는 성능향상폭을 기록하게 되었다.
(※ 역자 주 : 맥스웰 이후 딥러닝에 특화하는 방향으로 아키텍처를 개량하던 엔비디아는 GP100과 나머지를 서로 다른 분야에 최적화하는 모험을 단행했다. 최상위 칩셋인 GP100은 FP64, FP16에 집중하게 되었으며 GP102와 GP104는 INT8을 배타적인 특기로 갖게 된 것. 따라서 딥러닝의 분야 중에서도 FP16이 중시되는 신경망훈련(NNT)용으로 GP100가 탑재된 테슬라 P100을, INT8이 중시되는 신경망추론(NNI)용으로 GP102 / GP104가 탑재된 테슬라 P40 / P4를 내놓은 것이다. GP100보다 GP102가 더 간소하고(FP64의 부재, HBM2의 배제, 그래픽 출력 기능의 존치 등) 저가형 칩셋이기는 하나 용도를 살펴보면 둘은 상하관계라기보다는 서로 다른 곳을 겨냥한 '투톱' 이라 보는 편이 더 정확하겠다.)
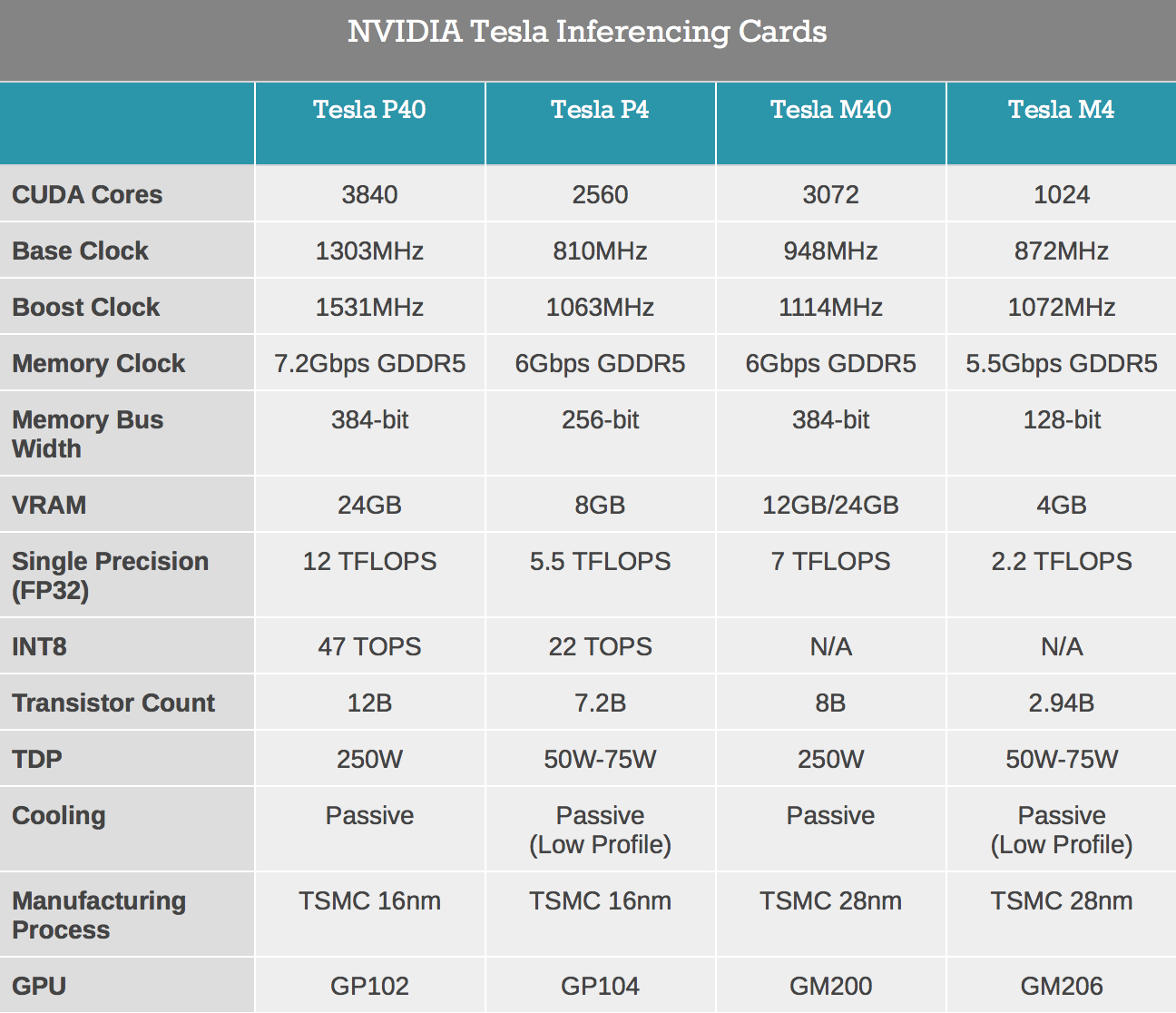
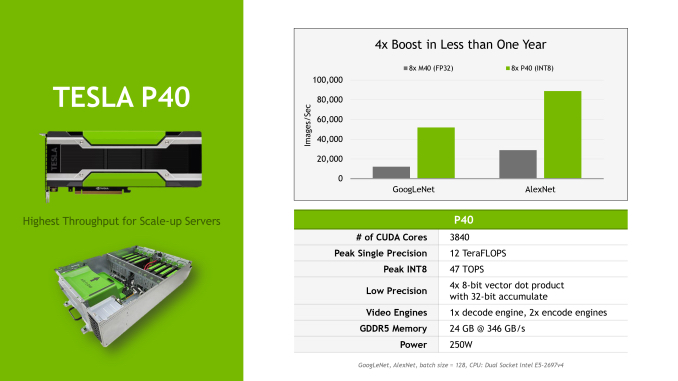
미안, 서론이 길었다. 백문이 불여일견이라고 제품들 각각을 좀더 자세히 살펴볼 차례. 오늘 발표된 두 모델 중 더 비싼 테슬라 P40부터 시작해 보자. 이름에서부터 테슬라 M40의 자리를 넘겨받을 포스가 마구 풍기지 않는가. 250W의 TDP와 풀사이즈 PCI-Express 슬롯 카드라는 점은 모두 전현세대가 공유하는 부분. 놀랍게도 이 모델은 GP102 GPU의 완전체를 탑재해 3840개의 쿠다코어를 가지며 평균 1.53GHz로 부스트되는 작동 속도를 자랑한다. FP64 / FP16을 제외한 연산성능 자체는 심지어 다섯달 전 발매된 테슬라 P100보다도 높다. (주 : 테슬라 P100은 GP102보다 상위 GPU인 GP100을 탑재했으나 쿠다코어가 3584개로 컷다운된 제원을 가지며, 작동 속도도 테슬라 P40보다 낮다.)
12 테라플롭스에 달하는 FP32 연산성능과 47 테라옵스(TOPS, Tera Operations per second)의 INT8 연산성능은 전세대와의 비교를 불허하는 수준. 테슬라 M40의 FP32 연산성능은 7 테라플롭스에 불과했고 INT8은 아예 지원조차 하지 않았다. 어마무시한 연산성능에 걸맞게 데이터를 끊김없이 공급할 메모리 역시 24GB로 넉넉히 탑재되었다. 고용량의 안정적인 구성과 소비전력 등을 고려해 타이탄 X에 사용된 GDDR5X 대신 7.2Gbps의 GDDR5 메모리를 탑재한 것 역시 특기할 사항.
좀더 우리의 지갑사정과 가까운 쪽으로 눈을 돌려 보면 테슬라 P4가 있다. 전세대의 테슬라 M4와 마찬가지로 로우 프로파일(LP, Low Profile) 규격의 아담한 크기에 보조전원 없이 구동되는 뛰어난 연비를 갖추고 있다. TDP는 50-75W로 커스텀 가능해 OEM 제조사에게 매력 포인트로 어필할 수 있을 것.
이 자그마한 껍데기 속에는 놀랍게도 GP104 GPU가 잠들어 있다. 그것도 쿠다코어 2560개가 모두 살아 있는 풀 칩으로. 그럼에도 이토록 연비가 좋아진 비밀은 무지막지하게 후려친 작동 속도에 있으니 테슬라 P4의 작동 속도는 기본 810MHz, 평균 부스트 1.06GHz에 불과하다. 8GB의 GDDR5 메모리를 탑재했으며 작동 속도는 6.0Gbps. 테슬라 M4가 2.2 테라플롭스의 FP32 연산성능을 가졌고 INT8을 지원하지 않은 것과 대조적으로 이 모델은 5.5 테라플롭스의 FP32 연산성능과 22 테라옵스의 INT8 연산성능을 자랑한다.
엔비디아는 왜 하필 같은 용도 -신경망추론- 를 갖는 연산장치를 두개나 출시한 것일까. 물론 폼팩터에 의한 시장 구분도 그 중 하나겠지만 무엇보다 중요한 것은 확장성의 차이에 있다. 테슬라 P40은 최고 성능의 단일카드 연산장치로 활용되기 좋지만 테슬라 P4는 고밀도 클러스터를 구축하기에 좋다. 이는 전력대 플롭스 비율을 보면 더욱 극명해지는데 테슬라 P40은 P4 대비 동일한 연산성능당 50%가량 더 많은 전력을 필요로 한다. 손꼽을 만한 숫자의 GPU로 빼어난 성능을 뽑아내야 하는 환경이라면 테슬라 P40을, 대규모의 GPU를 활용해야 하는 쪽이라면 테슬라 P4를 각각 킬러로 투입할 수 있다는 얘기다.
마지막으로 제일 중요한 것. 테슬라 신상 발표가 늘 그랬듯 시제품을 구입할 수 있는 시기는 조금 더 기다려야 할 것으로 보인다. 다만 엔비디아에 따르면 주요 OEM 및 채널 파트너에게는 오는 10월부터 테슬라 P40을, 그보다 한달 뒤엔 P4를 공급할 것이라고. 이들의 가격은 아직까지 공개되지 않았지만 상상을 초월하게 비쌀 것이라는 데엔 누구도 이견이 없을 줄로 안다. |
|||||







opinion