






| 제목 | 가난한 집 장남, 입신양명 꿈 가슴에 안고 : AMD Zen 아키텍처 분석 | 추천 | 0 | IP 주소 | 110.13.xxx.111 |
|---|---|---|---|---|---|
| 글쓴이 | 닥터몰라 | 날짜 | 2016.09.16 03:05 | 조회 수 | 9188 |
|
* 핫칩스 컨퍼런스가 막을 내린지도 벌써 2주가 지나 갑니다. 언더케이지 회원 여러분께서는 추석 연휴 즐거이 보내고 계신가요. 연휴의 마지막 날을 맞아 오늘은 근래 가장 '핫'하게 기대를 모으고 있는 CPU, AMD Zen의 아키텍처를 살펴보는 글을 준비했습니다. 재미있게 읽어 주시고, 이 글이 연말께 출시될 Zen의 성격을 이해하는 데 조금이나마 도움이 될 수 있길 바랍니다. 글쓴이 : 이대근 원문 : http://drmola.com/news/69245
지난주 Hot Chips 컨퍼런스를 거치며 AMD는 단연 뜨거운 감자로 떠올랐다. 수많은 이들을 설레게 한 인텔의 카비레이크, 애플의 애플워치 시리즈2와 아이폰7 출시, 그리고 -설렘의 장르는 조금 다르지만 어쨌든- 삼성의 갤럭시노트7에 이르기까지 기라성 같은 제조사들이 제각기 쏟아낸 이슈가 낭자했던 한 주였기에 이 모든 것을 뚫고 AMD를 향해 비춰진 스포트라이트는 더욱 곱씹어볼 만하다. 유례없는 강세를 보이는 주가를 비롯해 근래 거의 AMD의 멱살을 잡고 끌고가다시피 하고 있는 주역은 바로 새 아키텍처 Zen. 불도저 이후 자그마치 5년만이다.
Zen. 한때 실존 여부 자체를 의심받기도 했던 그 이름. 아마도 이를 불식시키기 위한 것이었겠지만 AMD는 Hot Chips 컨퍼런스에서 데모를 시연하며 영원한 경쟁사 인텔에 역대 최고수위의 도발을 날렸으니, 렌더링 어플리케이션 ‘블렌더’ 벤치마크 테스트에서 아주 근소하게나마 동클럭 동일 코어 개수의 브로드웰을 넘어서는 점수를 찍은 것이다. 물론 단 하나의 벤치마크인데다, AMD측의 변인통제라는 ‘신뢰의 한계점’ 또한 뚜렷할 뿐만 아니라 설령 신뢰할만한 변인통제가 되었더라도 렌더링 성능 하나만으로 CPU로서의 다면평가가 갈음되지는 않는다. 단적으로 싱글코어/싱글스레드 성능이 아직 베일에 싸여있지 않은가. 다만, 코어2듀오 이후 10년간 어떤 분야에서도 인텔과 대등하게 경쟁하지 못한 하이엔드 데스크탑 이상의 시장에, 적어도 ‘멀티코어 렌더링 성능’ 에 한해서라도 인텔을 확실히 넘어설 가능성이 생겼다는 의미를 애써 축소할 필요는 없겠다. AMD는 Hot Chips 컨퍼런스에서 Zen의 세부 구조에 관한 슬라이드를 제공했는데 이 글에서는 이를 통해 Zen이 불도저와 어떻게 다르며 또한 인텔의 아키텍처들과는 어떤 차이점과 공통점이 있는지를 간단히 짚어볼 것이다.
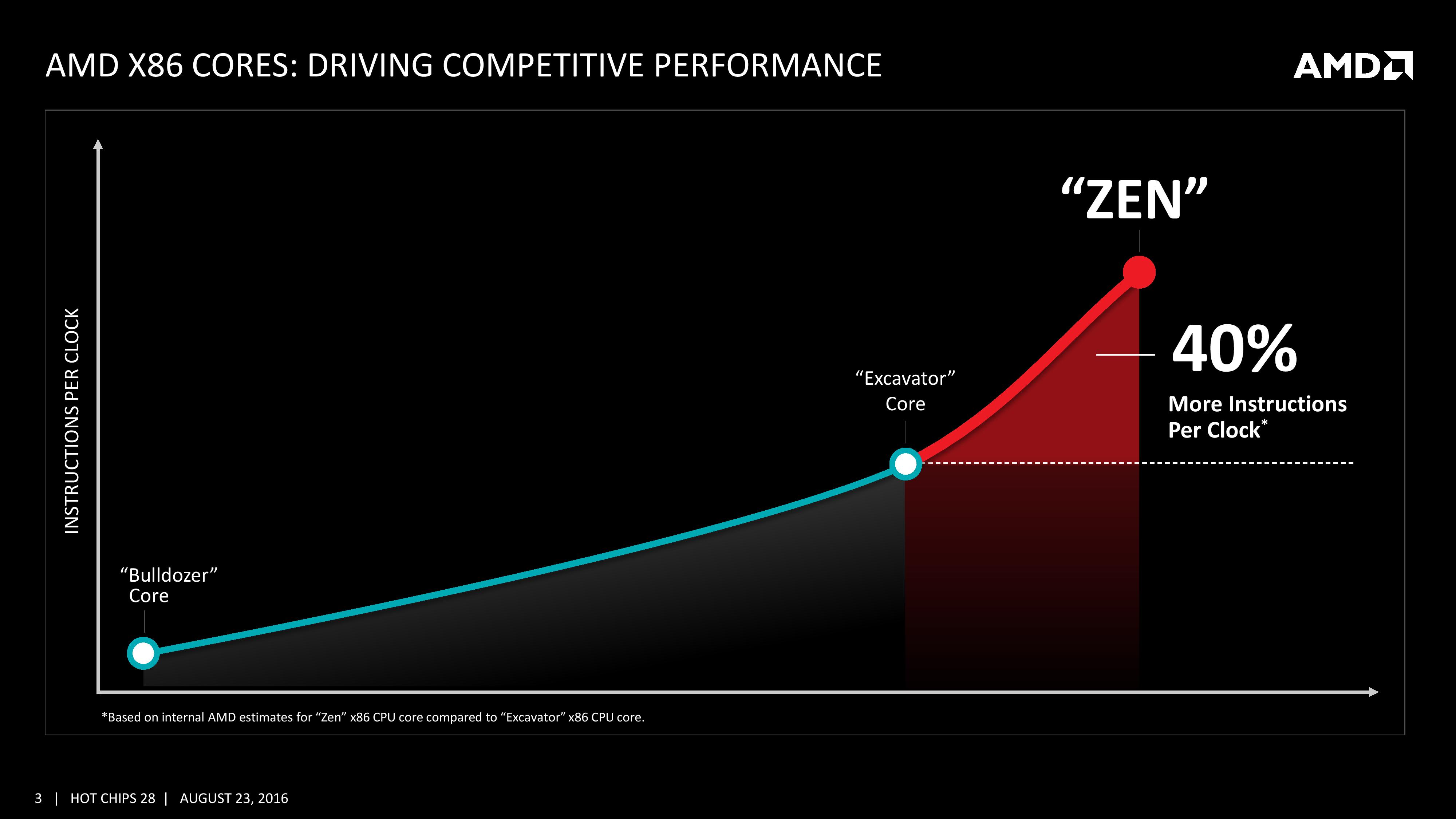
AMD는 앞서 지난해 5월 개최된 Financial Analyst Day 행사에서 Zen의 청사진을 처음으로 대중에 공개했었다. 엑스카베이터 대비 40% 향상된 IPC라는 목표는 이런 류의 발표가 으레 그렇듯 어느 정도의 수사적 과장이 포함된 것으로 받아들여졌다. 다시 말해, 이때까지만 해도 누구도 Zen이 '실제로' 40%의 급격한 IPC 향상을 이룩할 것이라고 짐작하지 않았다. 불도저의 IPC가 당시 인텔의 카운터파트였던 샌디브릿지 대비 60% 수준에 머물렀고, 이후 파일드라이버, 스팀롤러, 엑스카베이터를 거치며 매번 10% 안팎의 IPC 개선을 이뤘기에 여기에 다시 40%의 향상이 가해진다면 Zen의 IPC는 샌디브릿지의 110% 수준이 된다. 다시 말해 단번에 현세대 인텔 아키텍처(브로드웰, 스카이레이크)를 따라잡을 수 있게 된다는 뜻이다.
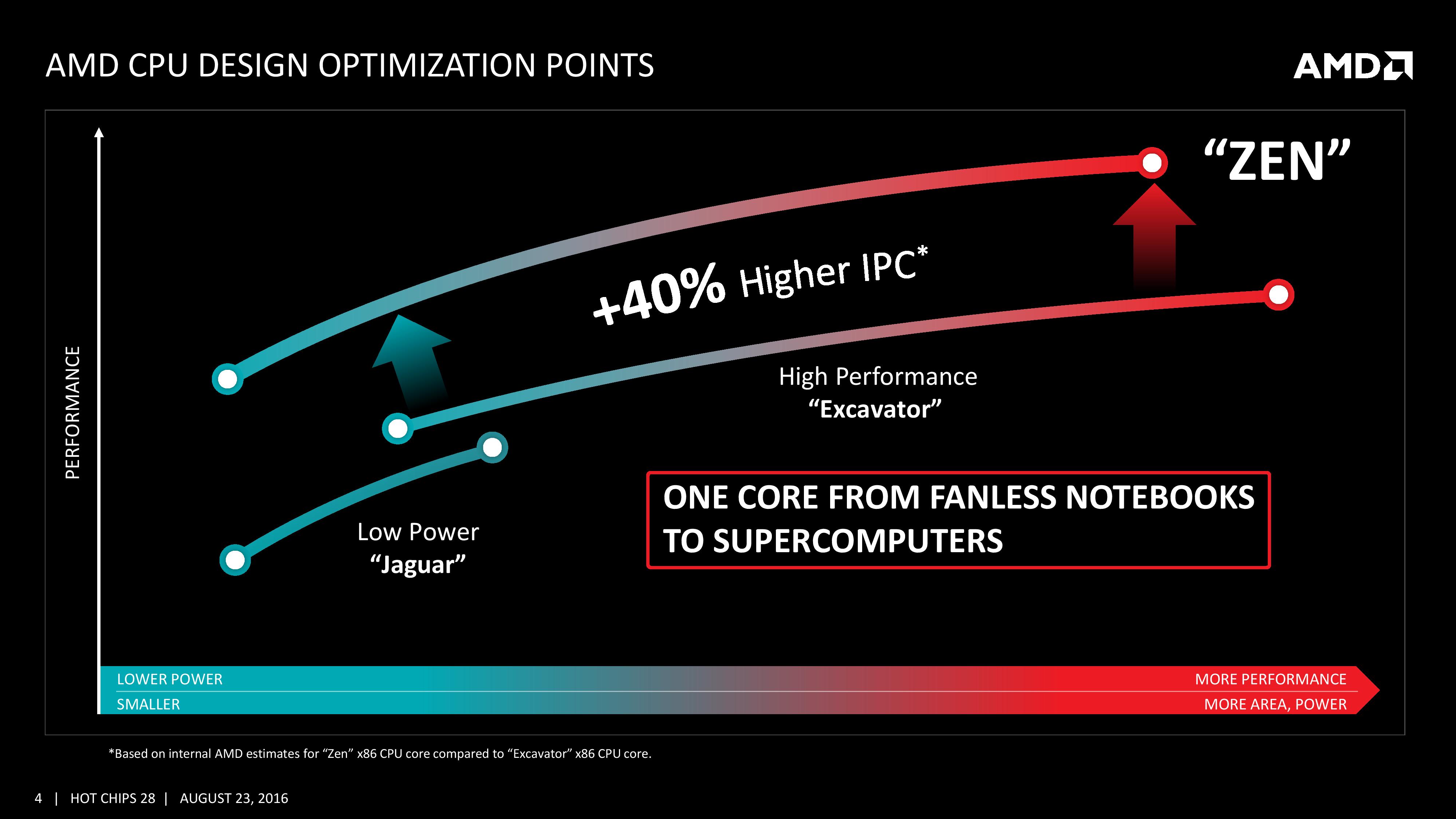
AMD에 따르면 Zen은 단순히 성능만을 개선한 아키텍처 또한 아니다. '팬리스 노트북' (다시, 필자는 이것을 인텔 코어 M급 라인업으로 받아들인다) 에서부터 슈퍼컴퓨터 (이것은 인텔 제온 E5/E7급 라인업으로 해석할 수 있을 것이다) 에 이르기까지 Zen이라는 단일한 아키텍처의 스케일링으로 대응하려면 필수적으로 갖춰야 할 덕목이 있으니, 그것은 전성비이다. 오늘날 재규어/퓨마와 엑스카베이터가 양분하고 있는 AMD의 x86 포트폴리오를 단일 솔루션으로 통합하는 의미 역시 Zen이 떠맡게 되었다. 어떻게 보면 인텔보다도 더 공격적인 행보라 할 수 있는데, 인텔은 아직까지도 주류 아키텍처(브로드웰, 스카이레이크)와 모바일 아키텍처(에어몬트, 골드몬트)를 병진시키고 있기 때문. 나아가 현재 재규어 기반의 SoC가 투입되는 게이밍 콘솔 시장에도 여차하면 Zen을 투입해버릴 수 있다는 의미이기도 하다.
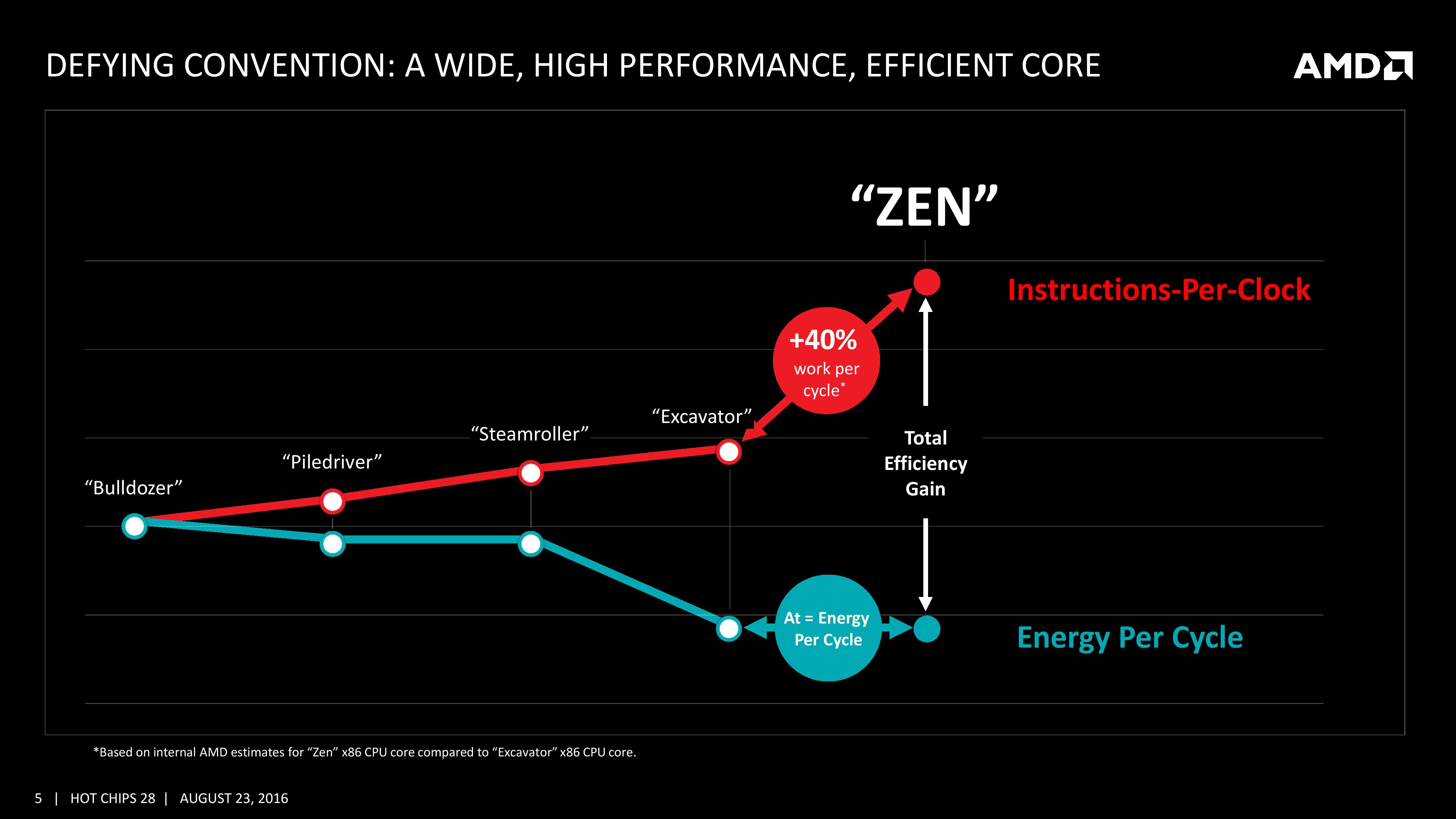
불도저 이후 등장한 3개의 아키텍처는 모두 소비전력을 조금씩 떨어뜨리면서 IPC를 올린다는 두가지 목표를 동시에 추구해 왔다. Zen에 들어서는 이 노선을 크게 변경, 소비전력을 전세대와 동일한 수준에 (정확히는 클럭이 같을 경우 소비전력이 같은 수준으로) 묶어두는 대신 IPC 향상을 극대화하기로 한 것 같다. 이를 바꿔 말하자면 엑스카베이터에서 AMD는 드디어 '만족할만한' 전력대비 클럭 비율을 달성했고 이를 더 고도화하는 것은 Zen 세대에서는 일단 보류한 것이다. 다만 스팀롤러와 동일한 28nm 제조공정에서 생산되는 엑스카베이터와 태생부터 14nm FinFET 제조공정에 맞춰진 Zen이 같은 수준의 전력대비 클럭 비율을 가진다는 것이 쉽게 납득되지는 않는다. 어쩌면 Zen의 전성비가 같은 FinFET 기반 CPU들에 비해 다소 떨어진다는 복선은 아닐까. 물론 우리 모두가 간과하고 있는 사실이 있으니 아직까지 엑스카베이터는 우리가 만져볼 수도 없는 신화 속 영물같은 존재라는 것. 그리고 최소한 위 자료에 따르면 엑스카베이터는 스팀롤러에 비해 비약적인 전성비 향상을 '이미' 이뤘다. 즉 '엑스카베이터와 동급'의 전성비라는 것에 아직은 기대도 실망도 이르다. 스팀롤러를 발표하며 AMD는 파일드라이버 대비 10%의 성능향상을 이뤘지만 동시에 달성가능한 최대 클럭이 정확히 10% 줄어드는 아픔을 겪었다. 따라서 스팀롤러는 FX 라인업에 진출 실패. 이후 비슷한 일이 엑스카베이터에서도 반복되었다. 설상가상 이쪽은 애초부터 모바일을 염두에 두고 전성비 개선에 집착한 덕분에 데스크탑용으로 출시할만한 최소한의 클럭을 달성하는 데에도 실패했다. 즉 Zen이 엑스카베이터의 (모바일급) 전성비를 유지하며 데스크탑급 클럭을 달성만 하더라도 큰 일을 해낸 건 맞다.
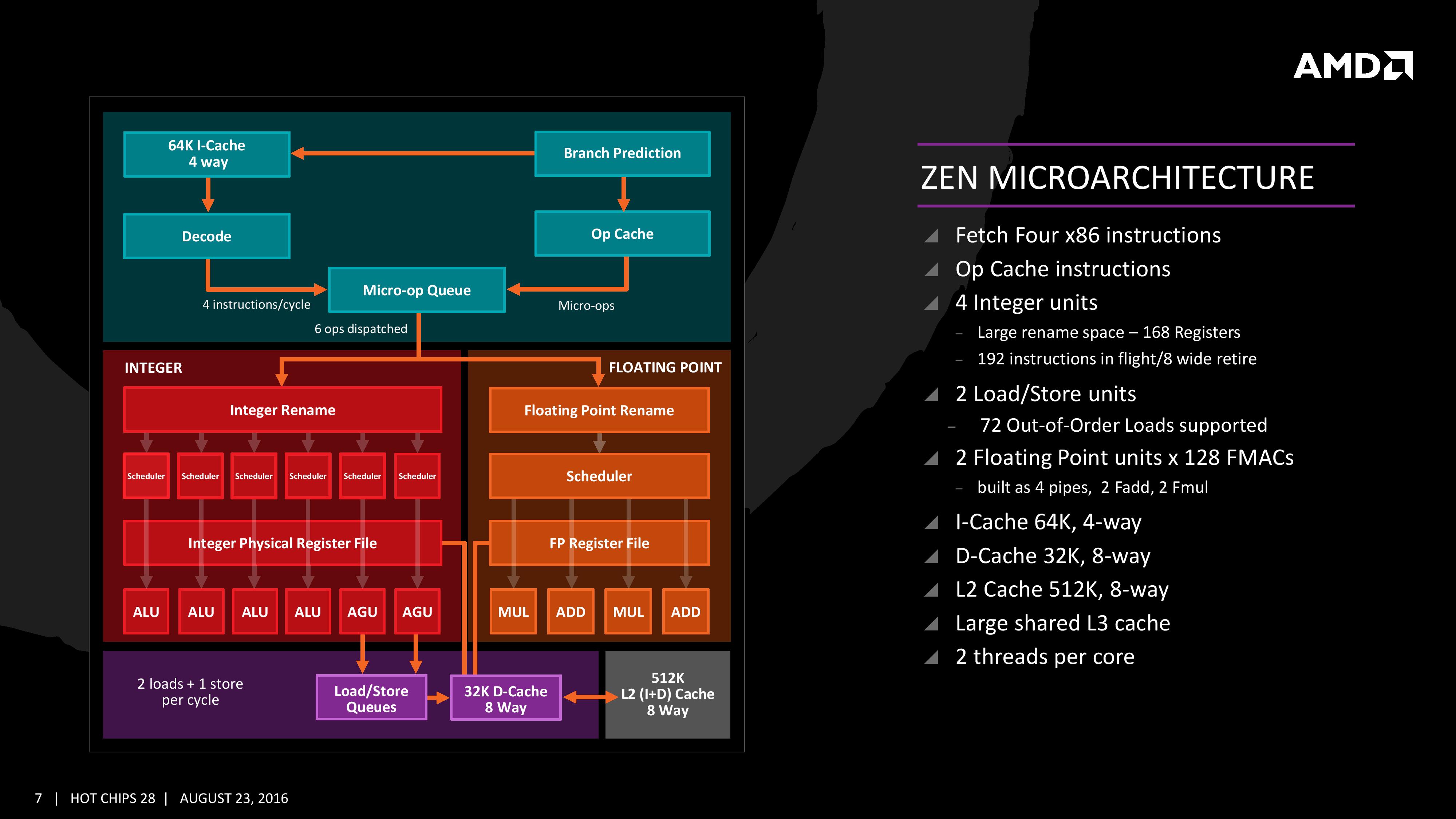
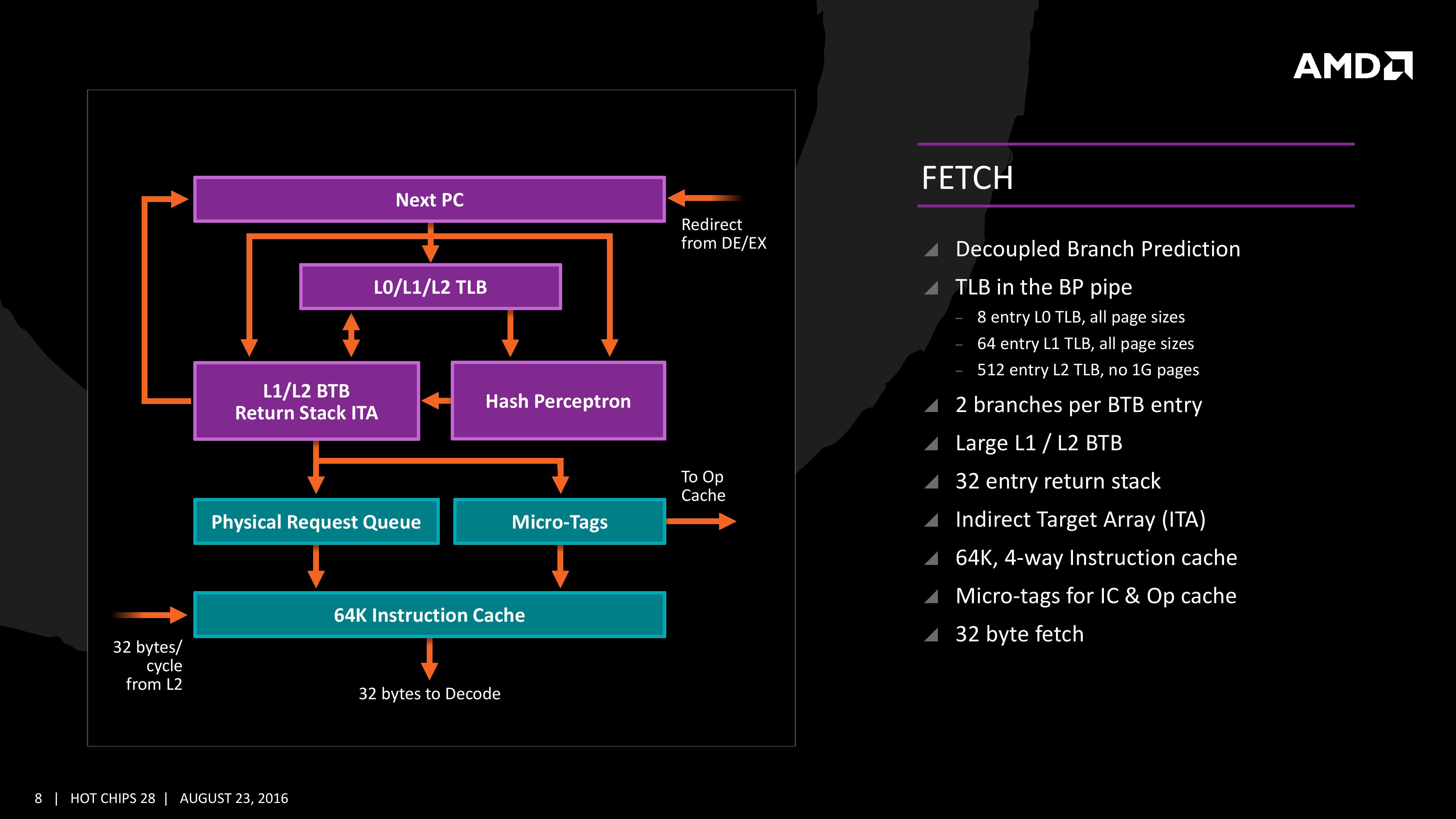
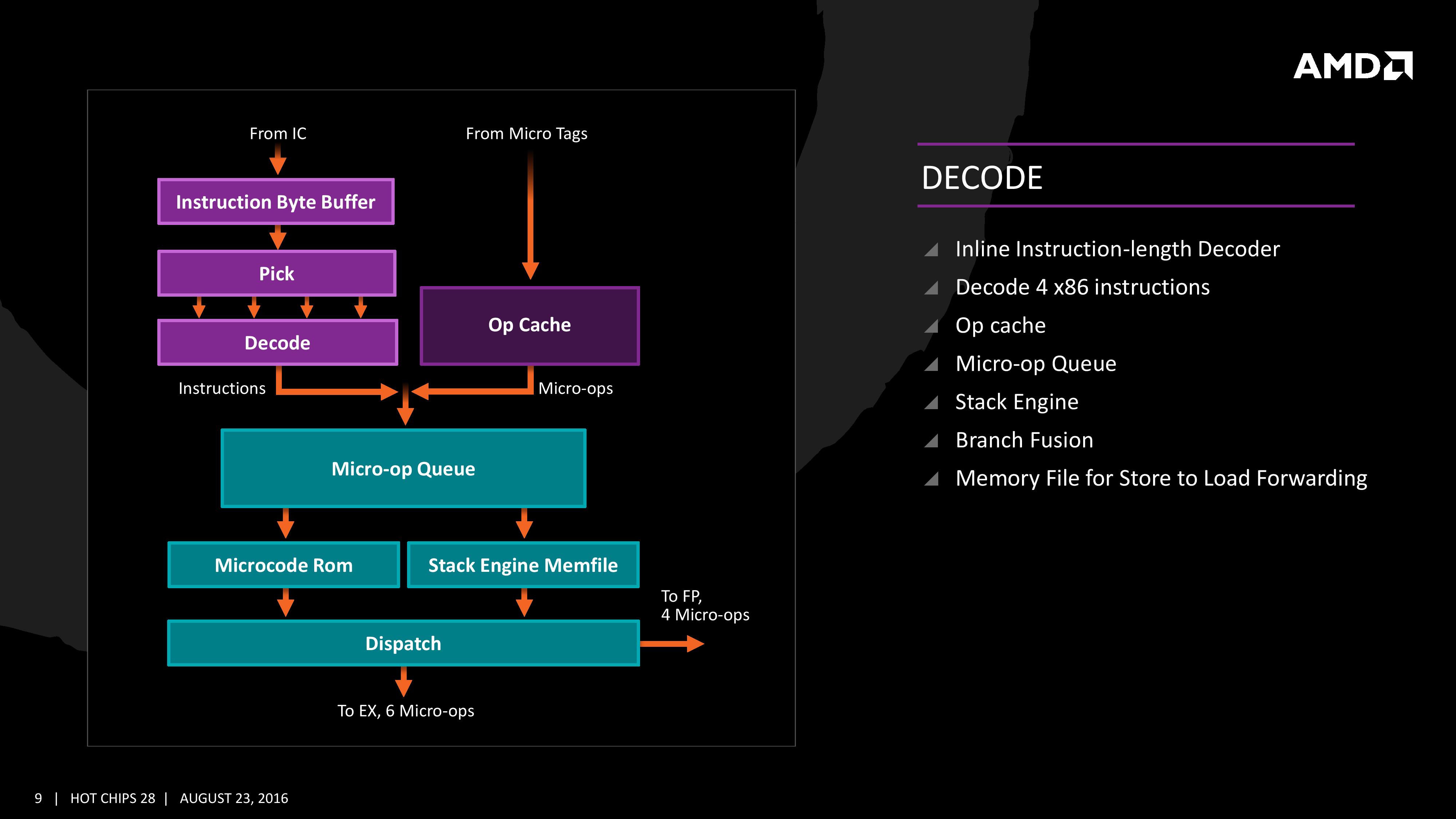
Zen의 특징은 크게 세가지 부문으로 나눠볼 수 있다. 첫번째로 가장 중요한 CPU 코어 아키텍처 자체의 개선, 두번째로 메모리 계층구조(캐시 시스템)의 개선, 마지막으로 목표수준의 전성비를 달성하기 위해 동원된 여러 기법들이다. 특히 주목할만한 것은 AMD 역사상 처음으로 동시 멀티스레딩(SMT, Simultaneous Multi-threading) 기술을 탑재해 1코어당 2개의 스레드를 병렬 처리할 수 있게 되었다는 점, 인텔의 마이크로옵 캐시(과거 넷버스트 시절로 거슬러 올라가면 트레이스 캐시)와 상동인 '옵 캐시' 를 신설했다는 점, 캐시 시스템이 전통적인 AMD의 그것에서 '인텔형'으로 탈바꿈했다는 점, 기타 프로세서 자원들(각종 연산유닛/큐, 캐시 용량/대역폭)의 아낌없는 확장 등이다. 이 모든 것을 앞으로 12장의 슬라이드에 걸쳐 차근차근 살펴볼 것이다.
앞에서도 언급했듯 이제까지의 AMD 아키텍처와 비교해 가장 크게 달라진 것은 옵 캐시의 신설이다. 여타 캐시가(디코드되지 않은) x86 명령어와 데이터를 저장해 두었다 필요한 경우 인출해 주는 것과 대조적으로, 옵 캐시는 이미 디코드된 마이크로옵을 저장한다는 차이점이 있다. 이 사소한 차이로 말미암아 옵 캐시가 인출해 주는 명령어의 이동경로는 현대 CPU의 내부에서 가장 오랜 작업시간이 소요되는 단계, '디코드' 스테이지를 생략할 수 있게 되었다. Zen이 탑재하는 옵 캐시의 용량과 대역폭은 아직까지 정확히 알려지지 않았으나, 보수적으로 보더라도 옵 캐시의 탑재가 가져다 줄 성능 향상폭은 과거 네할렘과 샌디브릿지 사이의 그것에 못지않을 것이다. 옵 캐시의 존재로 인해 디코더의 중요성이 크게 줄었음에도* 디코더 자체의 확장 역시 과거의 AMD 아키텍처와 비교하면 주목할만한 수준이다. 불도저는 (2코어) 모듈당 4개의 디코더를 탑재했으며 스팀롤러부터는 개별 코어의 독자성을 강화해 이를 (정수)코어당 2개씩으로 분절한 바 있는데, Zen은 이들보다 100% 증가한 '코어당 4개'의 디코더를 갖는다. 여기에 특정 x86 명령어 조합을 패스트 패스(fast path)에서 하나로 묶어 디코드할 수 있어 최종적으로는 사이클당 4~5개의 x86 명령어를 처리할 수 있게 된다. 이것은 브로드웰까지의 그것과 동일하고 스카이레이크보다는 1개 적다. 또한 디코더가 실시간으로 디코드한 마이크로옵 + 옵 캐시에 저장되었던 마이크로옵을 취합 재정렬해 백엔드로 보내는 역할을 수행하는 '마이크로옵 큐'는 최종적으로 사이클당 6개씩의 마이크로옵을 공급한다. 즉 프론트엔드의 마이크로옵 대역폭(in-flight microop)은 사이클당 6개로 스카이레이크의 그것과 같다. 그 외 백엔드부에 대해서는 잠시 후 다시 기술하겠다. (* : 인텔의 경우 넷버스트 아키텍처에서 트레이스 캐시를 신설하며 디코더를 극단적으로 삭감하기도 했다. 백엔드의 입장에서는 마이크로옵 캐시가 없을 경우 디코더가 마이크로옵을 생성하기만을 눈이 빠지게 기다려야 하지만 마이크로옵 캐시가 있다면 디코더로부터 병목현상이 발생한 경우라도 끊김 없이 마이크로옵을 공급받을 수 있다.)
프론트엔드부를 다시 세분화하면 명령어 인출(fetch)과 디코드 스테이지로 나눌 수 있다. 상대적으로 덜 부각된 인출 스테이지에서 특기할만한 점이라면 인출부와 독립적으로 작동하는(decoupled) 분기예측기(BP, branch predictor)를 탑재하고 있다는 점이다. 다만 독립 분기예측기 자체는 불도저에서도 채택하고 있던 것으로 완전히 새롭지는 않다. AMD는 Zen에서 분기예측에 이용되는 각 계층별 분기 타겟 버퍼(BTB, branch target buffer)의 용량이 '증대되었다'라고만 언급했을 뿐 정확한 제원을 알리지는 않았다. 다만 각 계층별 트랜슬레이션 룩어사이드 버퍼(TLB, translation lookaside buffer) 용량은 Zen의 성능을 가늠하는 간접지표가 될 수 있겠다. AMD의 과거 아키텍처들과 비교하면 이러하다. - K10 : L1 TLB 48-entry / L2 TLB 512-entry - 불도저 : L1 TLB 72-entry per 2 core / L2 TLB 512-entry (per 2 core) - 샌디브릿지 : L1 TLB 128-entry / L2 TLB 512-entry* - 하스웰 : L1 TLB 128-entry / L2 TLB 1024-entry* - 스카이레이크 : L1 TLB (?)-entry / L2 TLB 1536-entry* - Zen : L0 TLB 8-entry / L1 TLB 64-entry / L2 TLB 512-entry (* : 인텔의 경우 Unified TLB. 다른 대조군의 경우 명령어 TLB와 데이터 TLB가 분리되어 있다. 상술된 것은 명령어 TLB.) Zen 들어 L0 TLB가 신설되었으며, 역대 최대 용량의 L1 TLB, 그리고 불도저에서 폭락했던 L2 TLB 용량을 다시 과거 K10 수준으로 끌어올린 것으로 요약할 수 있다. 아주 러프하게, 분기예측은 버퍼 용량이 증가하는 비율의 제곱근(sqrt)에 비례하여 정확도가 높아지는 경향이 있다. 엄밀히 계량하기는 어렵지만 Zen의 분기예측 정확도가 과거 두 아키텍처를 뛰어넘는 수준일 것이라는 데에는 대체로 전망이 일치하리라고 본다. 한편 분기예측기를 거친 뒤엔 L1 캐시로부터 사이클당 32바이트의 x86 명령어를 인출해오게 된다. 위 슬라이드에는 L1 캐시가 어느 정도의 대역으로 인출할 수 있는지만 표기되었고, '명령어 페치 버퍼'의 용량은 기술되지 않았는데 비교해봄직한 다른 아키텍처의 사례는 아래와 같다. - K10 : 32B from L1-I Cache, 32B Instruction Fetch Buffer - 불도저 : 32B from L1-I Cache, 16B Instruction Fetch Buffer (per 2 core) - 샌디브릿지 : 16B from L1-I Cache, 16B Instruction Fetch Buffer - 하스웰 : 16B from L1-I Cache, 16B Instruction Fetch Buffer - Zen : 32B from L1-I Cache, (?)B Instruction Fetch Buffer
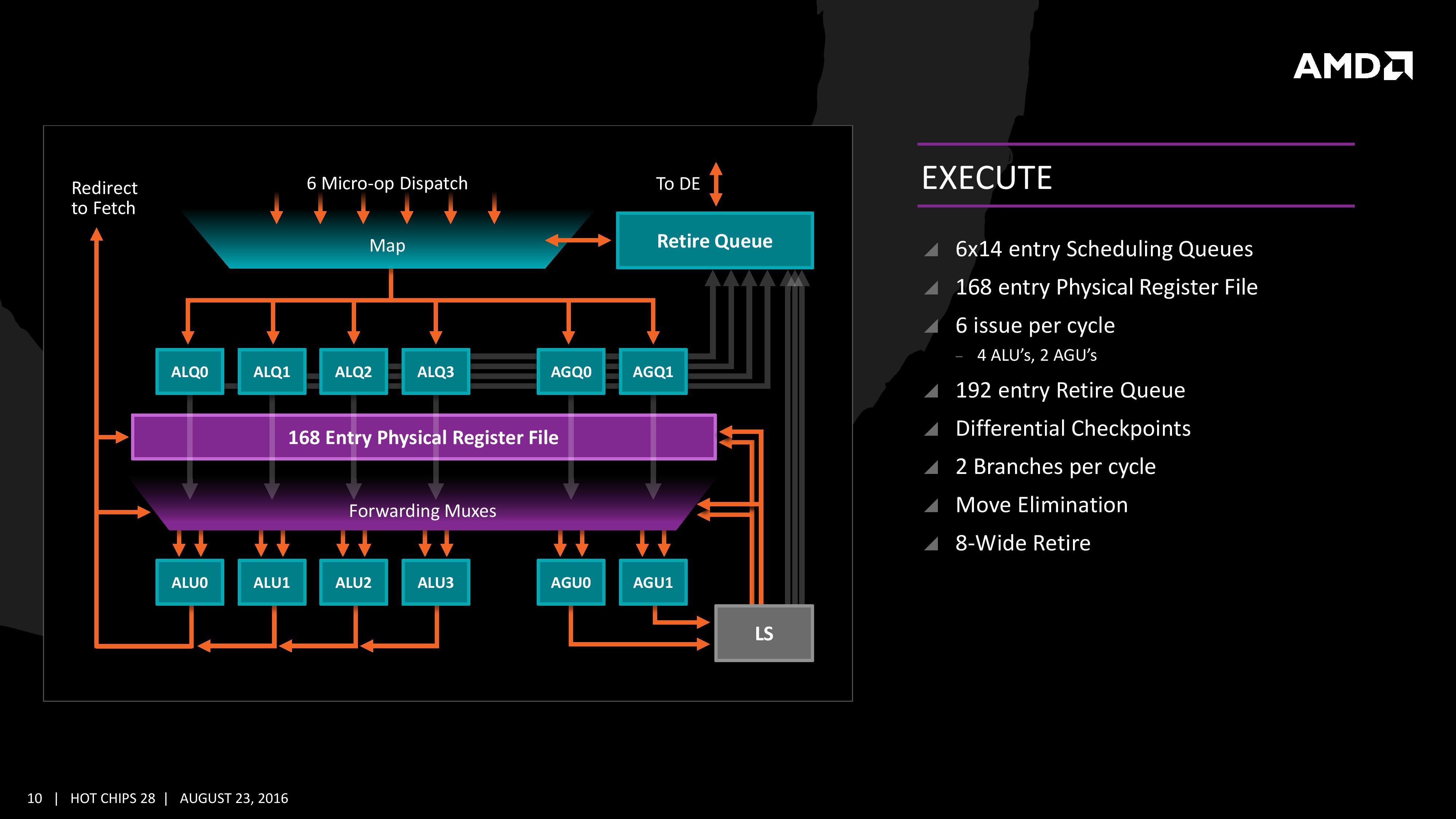
Zen의 디코더는 앞서 언급했듯 코어당 4개로 대폭 확장되었다. 디코더에서 갓 디코드된 싱싱한 마이크로옵과 옵 캐시로부터 인출된 묵은 마이크로옵이 뒤섞여 마이크로옵 큐에 저장되었다가 백엔드로 공급되며 그 대역폭은 사이클당 6개이다. 디코더는 x86 명령어 중 특정한 조합을 패스트 패스(fast path)로 보내, 두 개의 x86 명령어를 한 묶음으로 취급할 수 있으며 따라서 Zen 코어가 사이클당 처리 가능한 x86 명령어 개수는 4~5개로 유동적이다. 이 수치들이 인텔 브로드웰과 비슷하거나 비교우위, 스카이레이크보다 근소하게 비교열위이거나 동급이라는 점은 앞에서 살펴본 것들이다. 여기서는 이외의 장치들이 어떻게 작동하는지 구체적으로 짚고 넘어가고자 한다. 우선 마이크로옵 큐는 '원칙적으로' 마이크로옵만을 저장하는 것이 맞다. 그러나 너무나 전형적인 CISC인 x86 명령어는 (대부분 1-2개의 마이크로옵으로 변환되지만) 때에 따라 아주 복잡하게 다수의 마이크로옵으로 변환되기도 하는데, 이를 디코더가 처리하기에는 소요되는 시간이 너무 긴데다 실상 이러한 종류의 x86 명령어가 그리 많은 것도 아니다. 따라서 이들은 예외적으로 별도의 '태그'로써 마이크로옵 큐에 내려보내 두었다가 일종의 하드웨어적 변환 테이블(모든 경우의 수를 미리 내장한)인 마이크로코드 롬이 해당 태그에 맞춰 마이크로옵으로 바꿔 주는 단계를 밟는다. 디코드가 (정말로) 완료된 마이크로옵들은 디스패치 유닛으로 이동, 저장되어 있다가 적절한 시기에 백엔드로 공급(디스패치)된다. 디스패치 유닛의 대역폭은 사이클당 6마이크로옵으로 이전까지의 프론트엔드 내 in-flight 대역폭과 동일하다. 백엔드부는 후술하겠지만 정수 및 메모리부(이하 정수부)와 부동소수점부로 나뉘는데, 이중 정수부에 공급 가능한 최대 대역폭이 사이클당 6마이크로옵이며 부동소수점부가 4마이크로옵으로 이 둘을 단순 합산하면 디스패치 유닛이 최대로 공급 가능한 수량을 초과하게 된다. 현실적으로 백엔드의 모든 대역폭이 동시에 점유되는 경우가 거의 없어, 일반적으로 병목현상 예방을 위해 백엔드쪽을 여유롭게 설계하는 것이 보편적이다.
정수부는 168 엔트리의 스케줄러를 정점으로 각 이슈 포트(총 6개)별로 14개의 마이크로옵을 예비해둘 수 있는 구조(스케줄링 큐)를 갖췄다. 6개의 이슈 포트는 다시 4개의 정수연산유닛(ALU)과 2개의 주소생성유닛(AGU)으로 분배되며, 연산이 끝난 마이크로옵은 192 엔트리의 리타이어 큐에 집결되었다가 사이클당 8개씩 리타이어된다. 불도저의 경우 사이클당 4개씩의 마이크로옵을 리타이어시킬 수 있었다. 한편 주소생성유닛은 다시 로드/스토어 유닛으로 이어지는데 이에 관해서는 후술할 것이다. Zen과 비교해봄직한 다른 아키텍처의 사례는 아래와 같다. - K10 : 72-entry Reorder Buffer / 44-entry Integer Future File / 24-entry Scheduling Queue (8 x 3 ports) - 불도저 : 128-entry Retirement Queue / 96-entry Integer Register File / 40-entry Unified Scheduler - 샌디브릿지 : 168-entry Reorder Buffer / 160-entry Integer Register / 54-entry Unified Scheduler - 하스웰 : 192-entry Reorder Buffer / 168-entry Integer Register / 60-entry Unified Scheduler - 스카이레이크 : 224-entry Reorder Buffer / 180-entry Integer Register / 97-entry Unified Scheduler - Zen : 192-entry Retire Queue / 168-entry Physical Register File / 84-entry Scheduling Queue (14 x 6 ports) Zen의 정수 연산 유닛은 사이클당 2개의 분기 명령어를 처리할 수 있지만 모든 유닛이 동등한 기능을 갖지는 않는다. 정확히는 4개의 정수 연산 유닛 중 2개만이 분기 명령어를 처리할 수 있고, 1개는 정수 곱셈(IMUL) 명령어를 독점적으로 처리하며, 나머지 1개는 조건 레지스터(CRC)를 처리할 수 있는 등 다소간의 역할 분담을 꾀해 두었다. 물론 이러한 분업은 상술한 몇 가지 희귀한 케이스에서만이고 대체로 정수 연산으로 통용되는 모든 작업을 비교적 동등하게 수행할 수 있는 편이다.
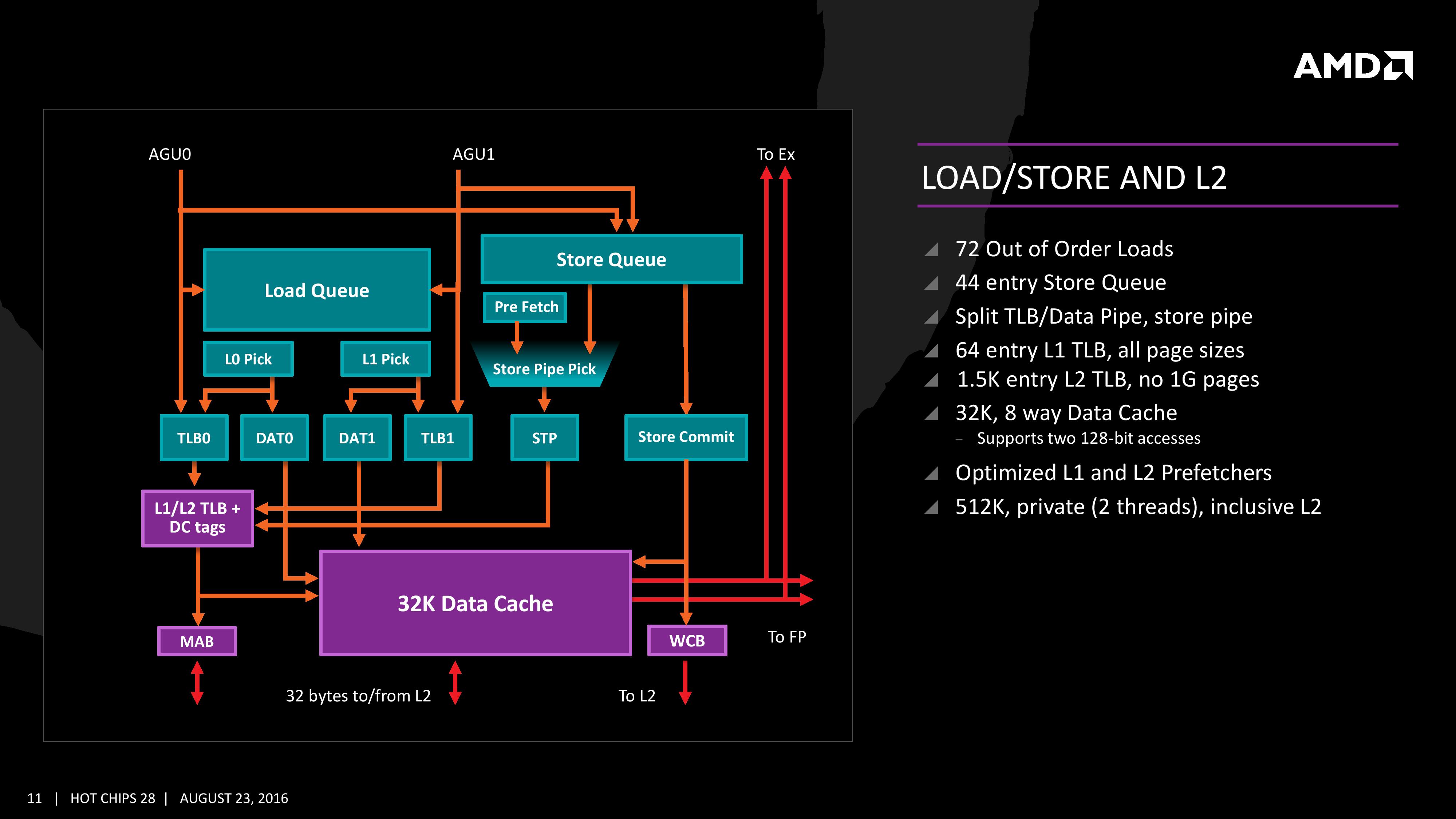
정수부(앞서 정수 및 메모리부를 줄여 정수부로 부르기 시작했음을 상기하자.)에서 로드/스토어 유닛만 따로 떼어 더 자세히 보면 위와 같다. 여기에는 각각 72 엔트리의 로드 명령과 44 엔트리의 스토어 명령을 큐에 저장했다가 적절한 때에 메모리에 보낼 수 있다. Zen과 비교해봄직한 다른 아키텍처의 사례는 아래와 같다. - K10 : 48-entry L1 DTLB / 656-entry L2 DTLB / 44-entry Load Store Unit - 불도저* : 32-entry L1 DTLB / 1024-entry L2 DTLB* / 40-entry Load Queue / 24-entry Store Queue - 샌디브릿지 : 64-entry L1 DTLB / 512-entry L2 TLB** / 64-entry Load Buffer / 36-entry Store Buffer - 하스웰 : 64-entry L1 DTLB / 1024-entry L2 TLB** / 72-entry Load Buffer / 42-entry Store Buffer - 스카이레이크 : 64-entry L1 DTLB / 1536-entry L2 TLB** / 72-entry Load Buffer / 56-entry Store Buffer - Zen : 64-entry L1 DTLB / 1536-entry L2 DTLB / 72-entry Load Queue / 44-entry Store Queue (* : 여기서는 불도저의 경우 정수코어 1개분을 의미. 단 L2 DTLB는 1 모듈(=2 정수코어)이 공유.) (** : 인텔의 경우 Unified TLB. 다른 대조군의 경우 명령어 TLB와 데이터 TLB가 분리되어 있다. 상술된 것은 데이터 TLB.) 여기서 중요한 것은 캐시 정책이 inclusive 방식으로 전환되었단 점이다. 불도저까지의(엑스카베이터를 포함한다) AMD 캐시 정책은 exclusive를 고수해 온 반면 경쟁사인 인텔은 한결같이 inclusive 방식을 채택했던 바 있는데 Zen은 오랜 고집을 꺾고 라이벌의 정책을 전격적으로 수용한 것이다. 또한 로드/스토어 유닛과 직접적으로 소통하는 L1 캐시를 디자인함에 있어 불도저에 적용되었던 Write-through 방식을 폐기하고 Write-back 방식을 도입했으며 이를 통해 ‘특정 코드 하에서 장시간 아이들에 빠지는’ 증상을 개선했으며, 또한 로드/스토어 유닛 자체의 레이턴시도 개선되었다고 한다. 그 외 Zen의 캐시에 관해 더 자세한 내용은 후술할 것이다.
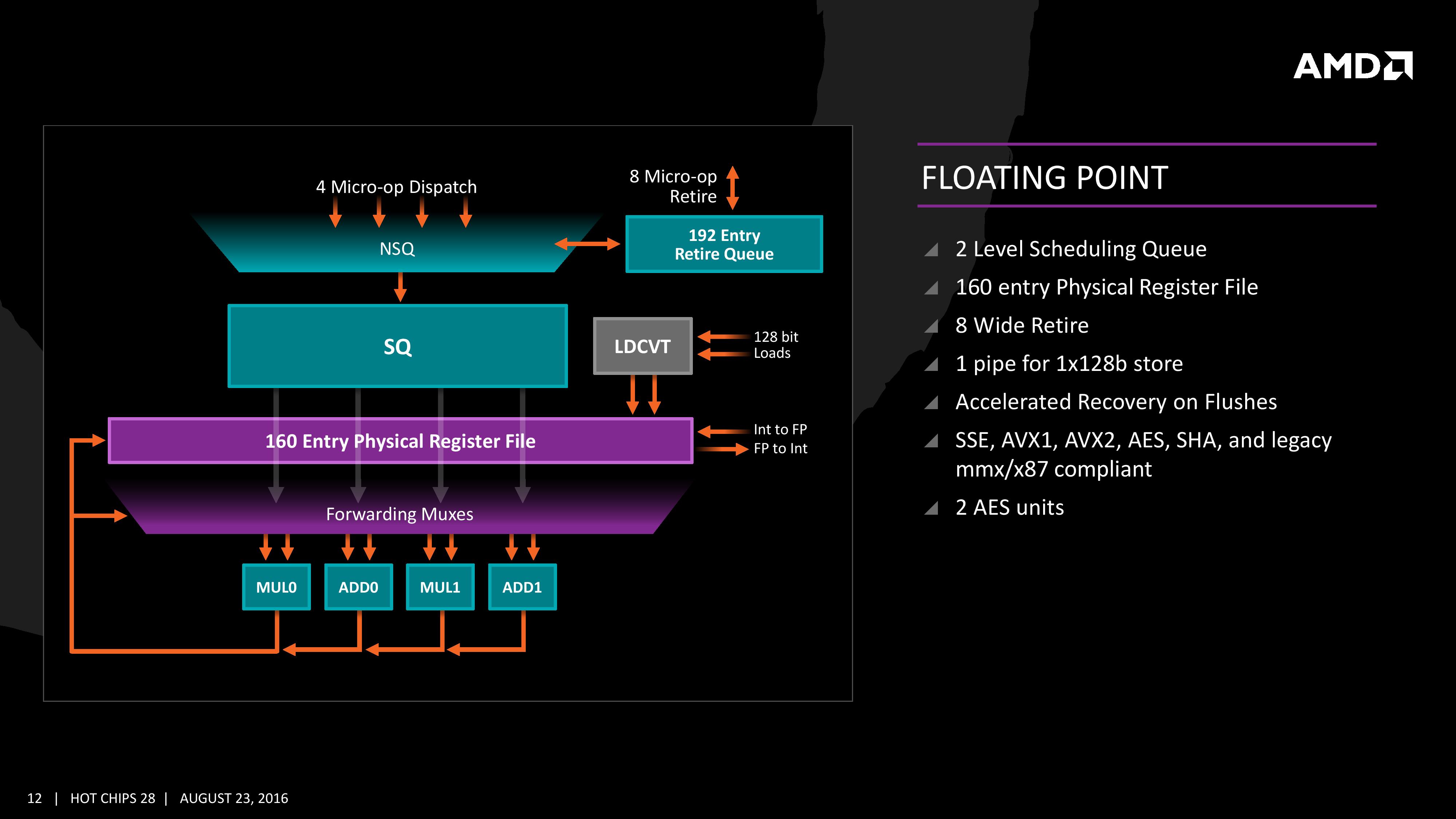
부동소수점부는 160 엔트리의 스케줄러를 정점으로 하고 있으며, 각 이슈 포트마다 스케줄링 큐를 배치했던 정수부와는 달리 통합된 '2계층 스케줄링 큐'를 탑재하고 있다. 디스패치 유닛으로부터 공급된 마이크로옵(사이클당 최대 4개씩 디스패치)은 상호의존성 및 저전력모드시 비순차수행의 선택적 배제 등을 고려해 ‘스케줄링 가능한 큐’(SQ)와 ‘스케줄링 불가능한 큐’(NSQ)로 분배된다. (정확히는 모두 NSQ를 거쳐 그 중 스케줄링 가능한 것이 SQ로 이동된다.) 스케줄링이 끝나면 마이크로옵은 스케줄러로부터 4개의 이슈 포트로 공급된다. 이들은 각각 2개의 ‘부동소수점 곱셈’ 및 2개의 ‘부동소수점 덧셈’ 유닛들이다(이하 FPU). 각각의 덧셈-곱셈 FPU가 짝을 이뤄 하나의 128비트 FMAC 명령어에 대응할 수 있으며, 또한 각각의 FPU는 256비트 AVX 명령어를 2사이클당 하나씩 처리할 수 있다. 이는 불도저의 두 배에 해당하며 인텔 브로드웰과 동일한 것이다. 지금까지 살펴본 백엔드 전체를 총괄하여, Zen과 비교해봄직한 아키텍처들의 ALU / AGU(메모리 접근 유닛) / FPU 포트 수를 정리해 보면 아래와 같다. - K10 : 3 ALU / 3 AGU / 2 FPU - 불도저 : 4 ALU / 4 AGU / 2 FPU (per 2 core) - 샌디브릿지 : 3 ALU / 3 LSU / 2 FPU (ALU와 FPU는 총 3개 포트를 공유) - 하스웰 : 4 ALU / 4 LSU / 2 FPU (ALU와 FPU는 총 4개 포트를 공유) - 스카이레이크 : 4 ALU / 4 LSU / 2 FPU (ALU와 FPU는 총 4개 포트를 공유) - Zen : 4 ALU / 2 AGU / 4 FPU Zen은 불도저보다 100% 더 많은 ALU와 FPU를 가지며 K10과 비교하면 각각 33%, 100% 더 많아진 것이다. 불도저는 2개의 정수코어가 부동소수점부를 공유하는 구조임을 생각하면 1 코어당 FPU 수는 300% 증가한 것과 같다. 특히 샌디브릿지/하스웰 대비 50% 수준으로 떨어졌던 불도저의 부동소수점 연산성능이 비로소 회복되었다는 의미가 있는데, 유닛 수 자체는 Zen이 두배 더 많지만 샌디브릿지/하스웰의 FPU는 256비트 AVX 명령어를 한 사이클에 처리할 수 있어 전체적으로 스루풋은 같다. 무엇보다 백엔드 전체의 이슈 포트 대역폭이 10개로 늘어 불도저 대비 100% / 샌디브릿지 대비 67% / 하스웰/스카이레이크 대비 25% 증가한 규모를 갖추게 되었다.
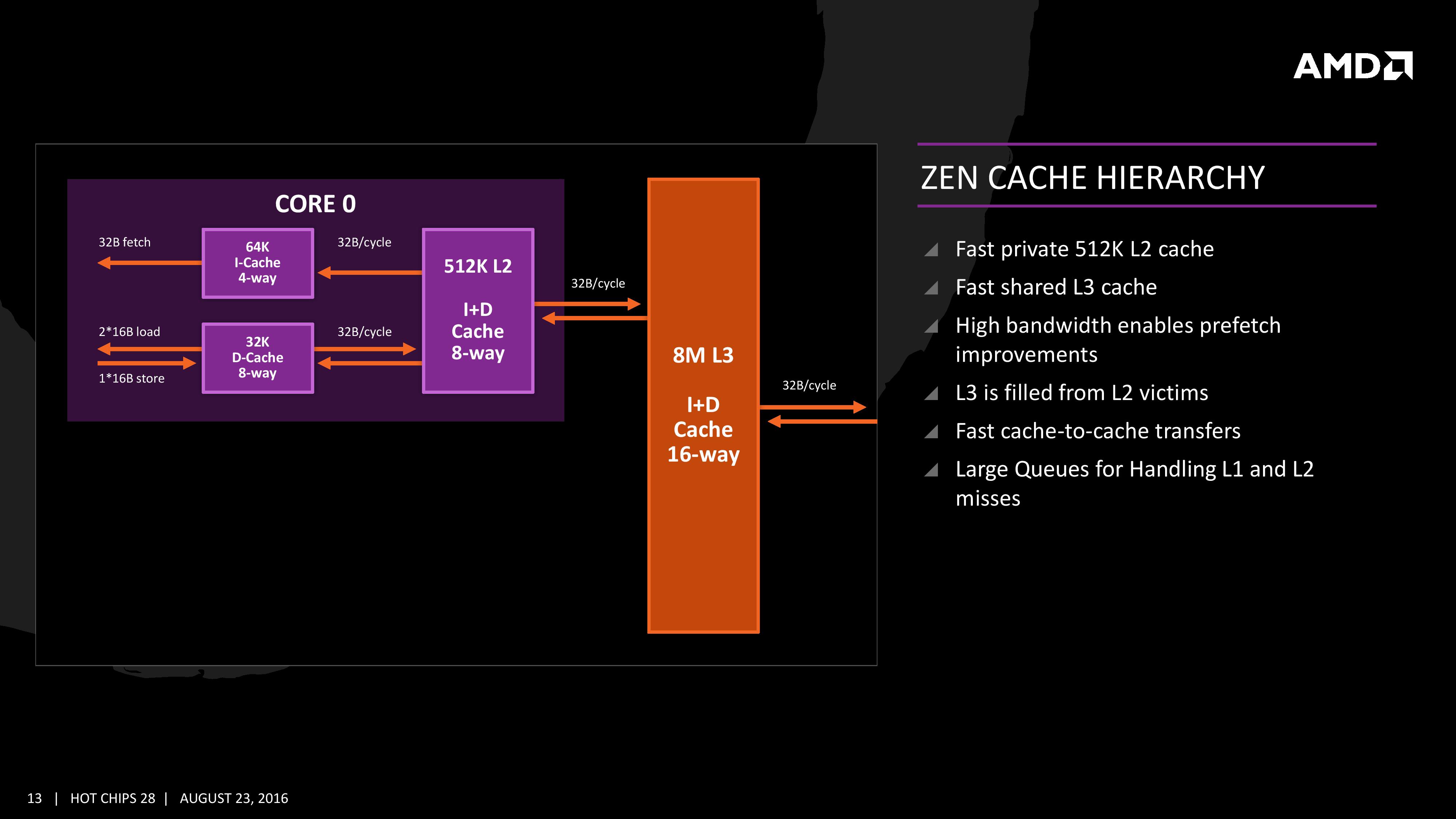
앞서 Zen부터 L1과 L2 캐시가 inclusive 방식으로 전환되었음을 지적했었다. 반면 L3 캐시는 여전히 exclusive 방식을 고수했는데, 정확히는 상위 계층 캐시로부터 방출된 내용물을 담아 두는 빅팀 캐시(victim cache)로서 설계되었다. 그 밖에도 불도저의 L2 캐시가 1 모듈(=2 정수코어) 내에서 공유되던 것과 달리 Zen은 코어당 512KB씩의 L2 캐시를 할당하는 것도 차이점이라 할 수 있겠다. 이로써 코어당 L2 캐시 용량 자체는 인텔의 최신 아키텍처들보다도 두배 더 많아졌다. (다만 L3 캐시까지로 눈길을 돌려 보면 여기서는 인텔과 AMD 모두 코어당 2MB의 용량과 16-way 집합 연관성으로 동일하다.) 이렇듯 고층위 캐시에 더 많은 자원을 투입했다는 사실은 Zen의 설계목표상 우선순위가 분명 싱글스레드 성능을 개선하는 데 있었음을 의미한다. Zen과 비교해봄직한 다른 아키텍처의 사례는 아래와 같다. - K10 : L1-D 64 + L1-I 64KB / L2 512KB / L3 1.5MB per core - 불도저 : L1 16*+64KB / L2 512KB / L3 2MB per 2 core (* : dedicated to an integer core) - 샌디브릿지 : L1 32+32KB / L2 256KB / L3 2MB per core - 하스웰 : L1 32+32KB / L2 256KB / L3 2MB per core - 스카이레이크 : L1 32+32KB / L2 256KB / L3 2MB per core - Zen : L1 32+64KB / L2 512KB / L3 2MB per core 이외에도 정확한 수치가 공개되지는 않았으나, AMD의 발표에 따르면 캐시 대역폭이 불도저의 다섯배 수준으로 향상되어 레이턴시를 크게 개선할 수 있었다고 한다. 불도저의 성능이 기대 이하였던 원인으로 지적된 것 중 하나가 저조한 캐시 성능이었음을 생각하면 분명 옳은 변화다.
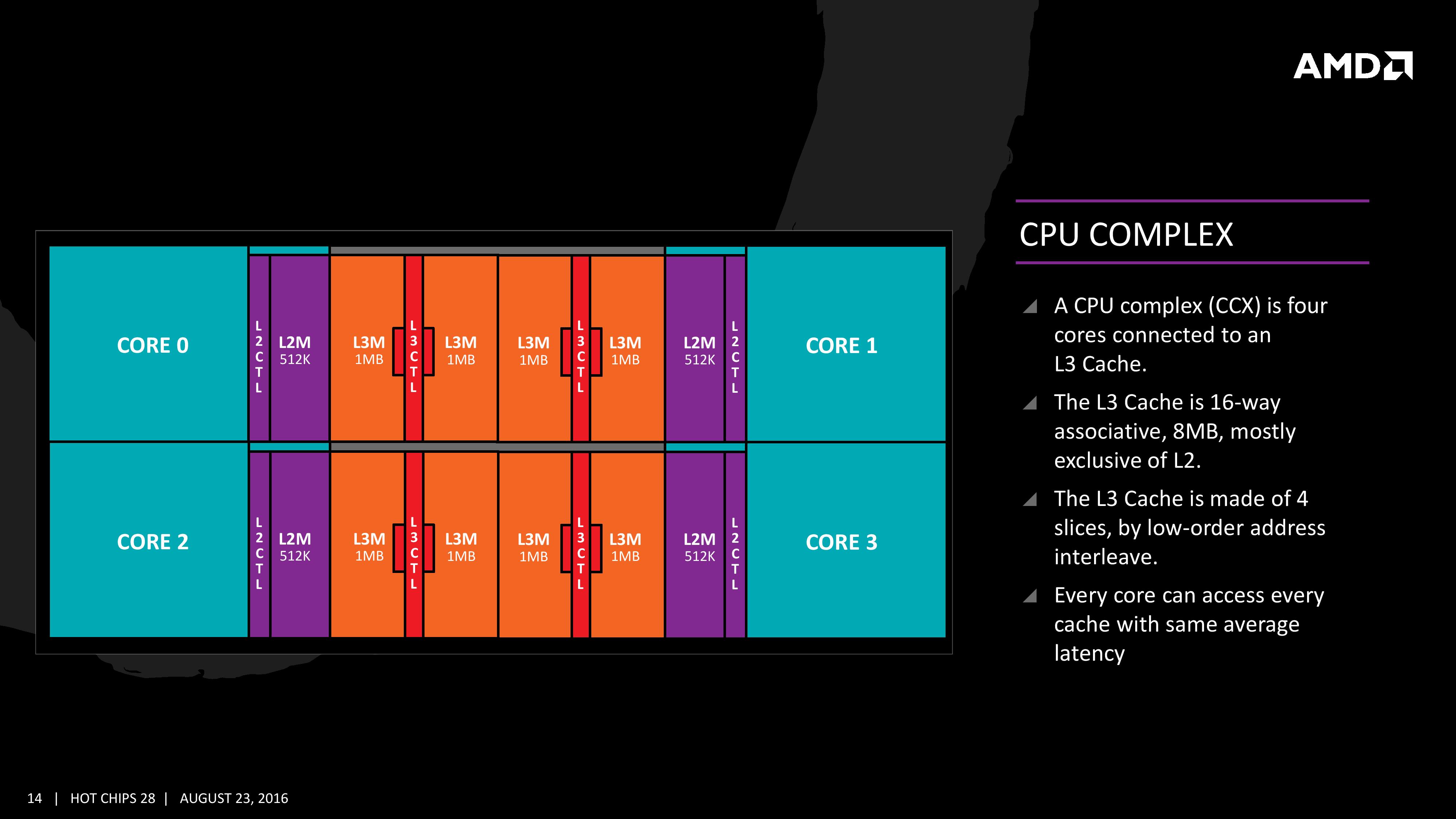
지금까지 코어 내부를 미시적으로 살펴봤다면 한번쯤 멀찍이 떨어져 숲을 볼 차례다. 2개의 코어를 일부 기능을 중첩시키며 융합해 하나의 '모듈' 단위를 만들어낸 불도저와 같으면서도 다른 'CCX' 단위가 소개되었다. 코어 컴플렉스 또는 CPU 컴플렉스라고도 불리는 이것은 4개의 Zen 코어를 하나로 묶은, 향후 Zen 기반 CPU들이 취할 기본 구성단위로 불도저와 다른 점이라면 각 코어의 어떤 기능도 중첩시키거나, 공유하는 방식으로 덜어내지 않았단 점이다. 구체적으로 코어부터 L2 캐시에 이르기까지의 자원은 모든 코어 개별적으로 향유하며 L3 캐시를 4코어가 공유하는 방식으로, 인텔의 4코어 데스크탑 CPU와 유사한 구조라 볼 수 있다. 다만 모든 코어가 모든 L3 캐시 슬라이스에 동일한 레이턴시로 접속한다는 설명으로 미루어 링버스 형태는 아닐 것으로 짐작된다.
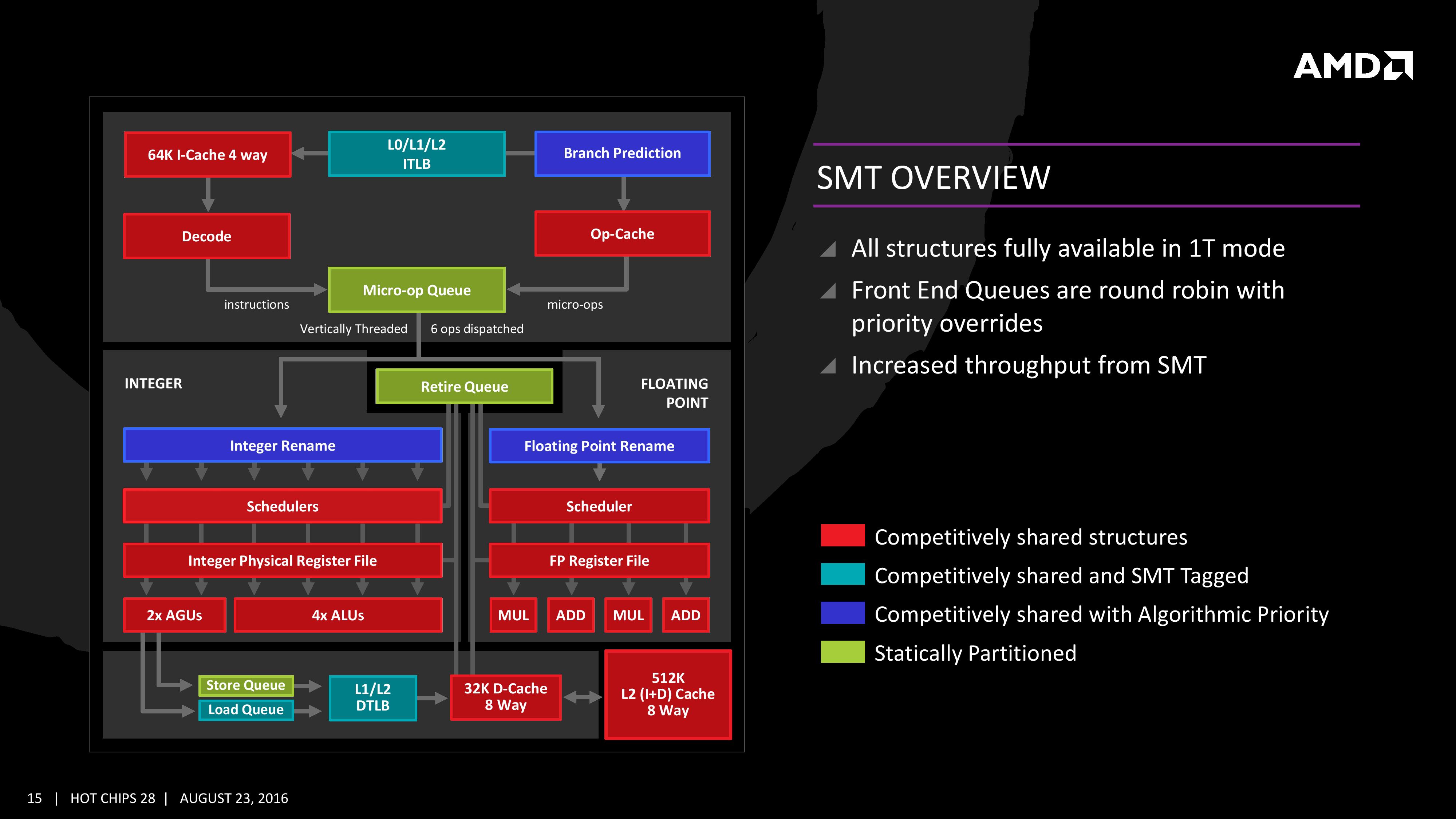
마지막으로 Zen이 구현한 SMT에 대해서 짚어볼 차례다. 가장 중요한 것은 부동소수점부 한정으로 사실상 SMT를 구현했던 불도저의 전철을 밟지 않는 것. 불도저는 모듈 내 1개의 스레드만 유입된 경우라도 모듈의 모든 자원을 활용하지 못하는 약점을 안고 있었고 이는 고스란히 싱글스레드 성능의 파탄으로 이어졌다. 따라서 1 스레드 모드에서도 코어 내의 모든 자원의 활용을 보장하는 것은 Zen에게 선택이 아닌 필수였을 것이다. SMT가 적용된 경우, 기본적으로 프론트엔드가 취하는 스케줄링 방식은 시분할(time-slice), 흔히 라운드 로빈 스케줄링이라 부르는 방식이다. 다만 우선순위가 전혀 고려되지 않는 순수 라운드 로빈 방식 대신 필요한 경우 우선순위를 부여할 수 있는 수단을 가미하여 변형한 알고리즘을 사용한다. 위 그림에서 파란색으로 표시된 부분은 '알고리즘에 의해' 투기적으로(speculatively) 우선순위를 판별하는 것으로 분기예측기와 정수/부동소수점 스케줄러가 이에 해당한다. 반면 녹색으로 표시한 것은 매우 정적인 방식으로 두 스레드의 공간을 분리하는데, 대부분 비순차수행을 고려할 필요가 없는 순차수행(In-Order) 방식 유닛들에 이에 해당한다. 청록색은 스레드 자체적으로 우선순위를 태그해 둔 경우로 레이턴시가 대단히 중요한 터치스크린 입출력 등의 작업이 이에 해당한다. 그 외 나머지는 각 스레드가 자유롭게 경쟁하여 필요한 유닛을 선점한 순으로 점유한다. 결국 이 모든 것은 Zen이 대단히 넓은 명령어 수준 병렬성(ILP, Instruction-level Parallelism)을 추구하고 있다는 것으로 요약된다. 물론 AMD의 기획의도를 총괄적으로 분석하기 위해서는 지금까지 살펴본 것보다도 더 상세한 정보가 있어야겠지만, 불도저보다 50% 넓어진 OoO 윈도우(Retirement Queue를 말함), 100% 증가한 이슈 포트 등 코어 구성의 급격한 확장은 명백히 SMT에 대응하기 위한 것이다. 부동소수점부를 두 코어 사이에 공유했던 불도저와 달리 Zen의 설계는 보다 인텔의 그것을 닮아 있으며, 따라서 불도저처럼 심각한 자원 경합(병목현상)을 겪지는 않을 것이다. 풍부한 자원이 뒷받침되는 한 SMT의 도입은 IPC를 상승시킬 가능성이 높다. 종합적으로, Zen은 역대 AMD의 아키텍처 중 가장 거대하고 체계적인 것으로 평가할 만하다. 우선 프론트엔드/백엔드의 거의 모든 요소가 자사의 과거 아키텍처(K10, 불도저)를 뛰어넘어 인텔 하스웰/스카이레이크의 사이에 위치하고 있으며 특히 백엔드와 캐시 시스템은 인텔의 최신 아키텍처를 뛰어넘는 제원을 선보였다. 물론 악마는 디테일에 있다는 오랜 관용구처럼, 장미빛 원석 같은 아키텍처는 파운드리가 어떻게 만들어내느냐에 따라 보석이 될수도, 돌이 될수도 있다. 개인적으로는 살펴본 슬라이드에서 유일하게 미심쩍인 부분이었던 전성비를 AMD가 어떻게 풀어내었을지가 궁금증으로 남는다. 그렇더라도 올 연말의 하이엔드 CPU 시장은 실로 오랜만에 후끈 달아오르게 생겼다. |
|||||



댓글 4
-
Soul:D
2016.09.16 03:43 [*.94.xxx.53]
zen코어와 RX490 기다린다 -
E717
2016.09.16 07:33 [*.111.xxx.73]
뭐든 독점은 안좋은 것이죠. 하루빨리 amd가 인텔과 같은 위치에서 경쟁하길 바랍니다. -
행복한은첼
2016.09.16 12:29 [*.62.xxx.119]
지금 겨우 스카이레이크 잡았는데....... 인텔은 7세대 발표했고.... 얼마나 안정성이 있을련지.... 롤퓨터로 카베리 7800 쓰느데 스노클링때문에.... -
vKPMSOv
2016.09.16 22:47 [*.9.xxx.178]
AMD가 이번에 폴라리스 기반인 rx480을 그런 가격에 그 성능으로 만든걸 보니 Zen도 암울하네요..