






| 제목 | Inside Your Xeon E5 V4 : 22코어 브로드웰-EP 전격 대해부 | 추천 | 0 | IP 주소 | 59.17.xxx.89 |
|---|---|---|---|---|---|
| 글쓴이 | 닥터몰라 | 날짜 | 2016.05.04 23:12 | 조회 수 | 6128 |
|
* 이 글은 단순히 '제온이 이런 것이다' 를 설명하는 것을 넘어, 장래에 제온을 구매할 가능성이 있는 예비 구매자들과 서버 관리자들, 프로페셔널들, 그리고 잘 모르지만 제온에 대한 막연한 동경을 가진 수많은 일반 유저들 - 폭넓은 스펙트럼에 걸쳐 있는 독자 여러분 모두에게, 제온이 구체적으로 어떤 사용자층을 겨냥했으며 각각을 대표하는 SKU에는 어떤 장단점이 있는지 등을 설명하고자 했습니다. 조금이라도 이 글이, 그런 면에서 도움이 될지 모르겠습니다. 독자 여러분께서 이 글을 끝까지 읽으셨을 때 제가 전달하기를 의도했던 내용의 일부라도, 어렴풋하게라도 이해하시고 재미있게 느낄 수 있다면 그 이상 바랄 것은 없습니다. 2년간 붙들어 온 글이 이제 막 제 손을 떠났습니다. 잘 부탁드립니다 :) 글쓴이 : 이대근 어시스트 : 이진협 원문 : http://iyd.kr/607
초판 발행으로부터 일년, 준비기간을 합치면 2년을 끈 제온 E5 리뷰를 이제야 탈고하게 되었습니다. 오랜 준비 끝에 선보이는 만큼 독자의 입장, 필자의 입장 모두에서 만족스러운 퀄리티를 담아내기 위해 많은 고민과 끊임없는 수정을 거쳤습니다만 최종 결과물 앞에 선 지금의 심정은 한없는 부끄러움 뿐입니다.
돌이켜보면 그간 이 글을 준비하는 과정은 국내에서 '진짜 제온'을 다루는 첫 리뷰로써, 톺아보고 싶었던 주제는 너무나 많고, 넓고, 깊었지만 정작 글쓴이의 역량이 그것들을 담아내기에 역부족이란 걸 내내 끊임없이 깨닫는 좌절의 연속에 다름아니었습니다. 독자 여러분께서 이 글을 끝까지 읽으셨을 때 제가 전달하기를 의도했던 내용의 일부라도, 어렴풋하게라도 이해하시고 재미있게 느낄 수 있다면 그 이상 바랄 것은 없습니다.
준비가 길었던 만큼 이 글이 빛을 보기까지 거의 대가 없는 도움을 준 많은 분들이 계셨습니다. 특히 가장 중요한 제온의 공수에 관해... 당연히 영리를 추구하는 회사로써, 제온의 총판으로써 '대가 없는' 도움을 주려 의도하신 건 아니었겠지만 리뷰가 너무나 늦어져 '사실상 무조건적인' 도움을 주신 것으로 변질(?)되어 버린 명인일렉트로닉스와 그곳에서 제 마크맨을 맡으셨던, 안타깝게도 이 글이 완성되는 것을 못 보고 이직하시게 된 김누리 전 대리님께 깊은 감사의 마음을 전합니다. 비단 이것 외에도 제온 E5가 사용된 모든 프로젝트(MakeItNano 1부 / 2부)에 함께해 주셔 큰 도움이 되었음을 이 자리를 빌어 고백합니다. 특히 명인일렉트로닉스는 제온 및 옵테론용 ASRock Rack 서버 메인보드를 대여해주기도 했는데, 역시 상술한 이유로 모든 조력은 '무조건적인' 것이 되었습니다.
더불어 항상 뛰어난 공수력으로 신제품들을 조달해 주신, 심지어 주력으로 다루던 모바일기기가 아닌 '제온 E5 V4' 샘플을 공수해주시기에 이른 언더케이지에도 머리 숙여 깊이 감사드립니다. 제온의 라이벌로 이 글의 핵심 조연인 옵테론을 조달해 주신 AMD 코리아의 권종욱 차장님, 메인보드, 메모리, 그래픽카드, 파워서플라이 등 테스트에 필요한 각종 컴포넌트에 대한 지난 2년간의 제 요청에 기꺼이 도움을 아끼지 않으셨던 엔비디아 코리아의 김선욱 이사님/박현정 차장님, 에이수스 코리아의 이상훈 팀장님/이종원 대리님, ITCM의 남대원 연구소장님/김해오름 대리님, EnigmaTnC의 홍가람 대표님과 코잇, 인텍엔컴퍼니에도 말로 다 못 전할 감사를 드립니다.
끝으로, 제게 생소했던 리눅스 환경을 구축하고 실행하는 데 절대적인 도움을 주셨던, 지금은 IYD의 개발팀장으로 더 큰 도움을 주고 계신 전 ITCM 칼럼니스트 김태현님께도 특별히 감사의 말을 전하고 싶습니다. 서버용 CPU의 대표 격인 제온을 도마 위에 올린 이상, 서버 / HPC 어플리케이션의 절대 다수를 차지하는 리눅스 환경에서의 벤치마크를 하지 않는다는 건 그 자체로 반쪽짜리 리뷰밖엔 될 수 없음을 의미했습니다. 태현님은 CUI에 전혀 익숙치 않았던 제가 스스로 터미널을 열어 커널 컴파일을 할 수 있게 되기까지 하드캐리해 주신, 이 리뷰를 가능케 한 숨은 주역입니다. 아울러 지금껏 언급한 이들의 도움 중 어느 것 하나라도 없었다면 이 글은 절대 완성되지 못했을 것입니다.
무엇보다 이 글을 포함해 모든 글들을 기획하는 저의 원동력이자 꼬박꼬박 IYD에 찾아와 제 글을 읽어 주시는 독자 여러분께 가장 큰 감사를 드립니다.
<목차>
1. 제온의 고대사 : P6부터 네할렘까지 2. 제온의 근대사 : 샌디브릿지부터 아이비브릿지까지 3. 제온의 현대사 : 하스웰부터 브로드웰까지 4. 제온 E5와 E7의 차이 5. 벤치마크 준비 : 대조군 선정 6. 벤치마크 결과 : (1) 3D 게임 및 멀티미디어 7. 벤치마크 결과 : (2) 연산성능, 암호화 및 파일 압축 8. 벤치마크 결과 : (3) 스눕 모드별 성능 비교 9. 결과 분석 및 트리비아 10. 결론
1. 제온의 고대사 : P6부터 네할렘까지
인텔이 데스크탑용과 구별되는 서버용 CPU를 출시한 것은 펜티엄 프로가 처음이었지만, 제온이라는 이름 자체는 펜티엄 2가 출시된 것과 같은 1998년에 그 하위 브랜드로써("펜티엄 2 제온") 세상에 첫 등장하게 되었습니다. 이때까지만 해도 인텔은 자사의 x86 포트폴리오 전체를 펜티엄이라는 단일 브랜드로 묶되 그 안에서 서버용에 적용 가능한 것에 제온이라는 꼬리표를 달아준 것에 지나지 않았습니다. 실제 펜티엄 2 시절과 3 시절의 제온은 그들의 데스크탑 카운터파트인 펜티엄 2 / 3과 비교했을 때 전혀 다르지 않은 코어 구성을 가졌으며, 기껏해야 캐시 계층 구조가 더 복잡해지거나 동일한 계층구조 하에서 캐시 용량을 늘린 수준에 그쳐 있습니다.
인텔이 제온이라는 이름을 독립된 브랜드로 사용하기 시작한 것은 그로부터 3년이 지난 2001년, 넷버스트 아키텍처를 도입하면서부터였습니다. 이때의 제온이 성공적이었는지 여부와 별개로 인텔은 넷버스트를 설계하며 그때까지의 패러다임을 완전히 버렸습니다. 파이프라인 자체를 고도화하기보다는 클럭을 높이는 방향으로, RISC와 정면으로 대결하기보단 아예 노선을 달리하는 것으로. 비슷한 시기 출시된 경쟁 RISC CPU인 파워PC 970 / 파워4 등과 정반대의 설계철학을 갖고 있었으며, 그들이 지향하지 않기에 충족시킬 수 없는 틈새시장에 자신들의 브랜드를 심을 결심을 하게 됩니다.
그러나 많은 분들이 이미 아시겠지만 넷버스트 자체는 그리 성공적이지 못했습니다. 넷버스트의 높은 부동소수점/낮은 정수성능이란 특성은 당시 서버에 요구되던 덕목과는 전혀 합치되지 않았습니다. 서버는 여전히 높은 정수성능을 요구했으며 넷버스트 제온으로 그 요구를 맞추기 위해서는 감당하기 힘들 만큼 클럭과 소비전력이 높아져야 했기 때문입니다. 오히려 제온 브랜드의 황금기는 넷버스트 후속으로 재등장한 개량된 P6, "코어" 마이크로아키텍처 시기에서였습니다. 그리고 그 다음 세대인 네할렘에서 제온은 일찍이 경험한적 없던 거대한 시장 확장을 맞이합니다.
네할렘은 x86 역사상 처음으로 비슷한 트랜지스터 수를 사용한 RISC와 정면대결을 시도해볼만 해진 아키텍처입니다. 프론트엔드 및 백엔드의 주요 구조는 코어 아키텍처에서 거의 달라지지 않았으나, AMD의 내장 메모리 컨트롤러로부터 영감을 받은 '언코어', AMD 하이퍼트랜스포트의 상동 기능인 퀵패스 인터커넥트(QPI) 등의 도입은 CPU 성능의 잠재력을 최대로 끌어내는데 한몫했고, 이러한 네할렘을 8코어 분량으로 확장한 네할렘-EX는 서버 시장의 RISC측 카운터파트였던 IBM POWER7, SunMicrosystems SPARQ T4 등과 비교했을 때 유의미한 가성비를 제공할 수 있었습니다. 이로써 인텔은 근 10년만에 최상위 서버시장에 진출할 수 있겠다는 자신감을 갖게 되었고, 다음 아키텍처인 웨스트미어에서 처음으로 제온 E7이라는 메인프레임급 대응 라인업을 발표하기에 이릅니다.
여기에 쓰인 웨스트미어-EX는 10개 코어를 탑재하고 있었는데, 당대의 데스크탑 CPU에 쓰이던 블룸필드/린필드보다 코어 수가 2.5배 많습니다. 이때부터 데스크탑과 서버 CPU의 양극화가 시작되어 그 다음 세대인 아이비브릿지-EP/EX에서 3.75배(15코어)로, 하스웰-EP/EX에서 4.5배(18코어)로, 마침내 오늘의 주인공 브로드웰-EP에서 5.5배(22코어)가 되는 등 현재진행형으로 확대되고 있는 실정입니다. 향후 수개월 내 출시될 브로드웰-EX는 24코어로 데스크탑의 6배, 스카이레이크-EP/EX는 32코어로 8배에 달할 것이라고 합니다.
2. 제온의 근대사 : 샌디브릿지부터 아이비브릿지까지
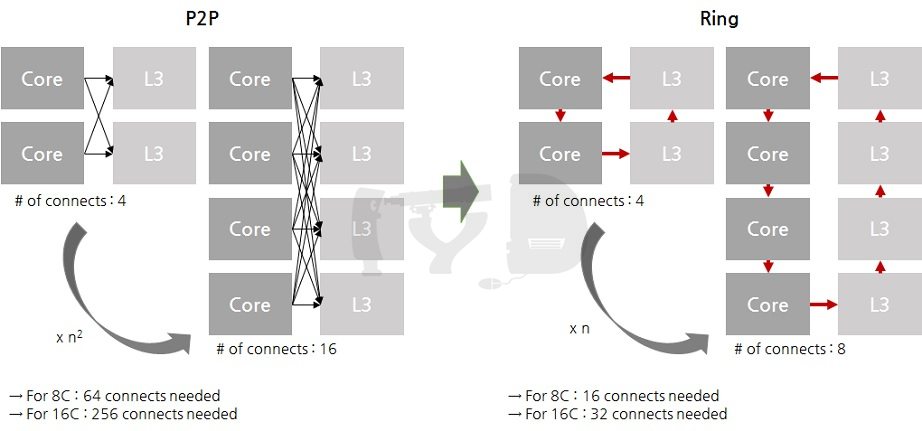
네할렘이 샌디브릿지로 대체되며 가해진 가장 큰 구조 변화는 바로 링 버스를 도입한 것입니다. 네할렘까지는 멀티코어 구성시 각각의 코어와 L3 캐시를 각각 독립된 채널을 통해 일대일로 연결해주어야 했고, 이는 균일한 캐시 액세스타임(UCA; Uniform Cache Access) 유지를 위해 당연한 것이었습니다. 그러나 많아 봐야 4코어가 끝인 데스크탑이나 8코어인 네할렘-EX까지만 하더라도 그로 인한 오버헤드가 심각한 수준이 아니었지만 코어 갯수가 10개를 넘은 웨스트미어-EX부터는 설계의 복잡성이 급격히 커지기 시작했습니다. 이래서는 미래에 코어 갯수를 늘릴 때마다 기하급수적으로 늘어나는 연결채널 수를 감당할 수 없겠다고 판단한 인텔은 샌디브릿지부터 링 구조를 도입합니다.
링 버스는 거시적으로 보면 UCA가 유지되나 미시적인 레벨에서는 분명히 Non-UCA(NUCA)라고 할 수 있습니다. 특히 여러 개의 코어가 탑재되는 서버용 다이에서 이런 특징이 두드러지는데, 예를 들어 0번 코어가 7번 캐시의 데이터를 접근할 때와 0번 캐시의 데이터를 접근할 때 소요되는 레이턴시가 명백히 다를 것이기 때문입니다. 그러나 각 코어와 캐시를 일대일로 이어주는 것보다 간단히 구현할 수 있다는 장점이 압도적으로 크게 평가되었고, 코어 갯수가 증가할수록 링 버스 구조로 인해 절약되는 복잡성이 미래에 큰 이득으로 환산될 것이었기에 이러한 결단이 내려진 것입니다.
한편 이 시기, 1세대 제온 E7으로서 샌디브릿지-EP의 상위에 투입된 선수는 한세대 전 아키텍처를 사용한 웨스트미어-EX였습니다. 처음이자 마지막으로 서로 다른 세대가 상/하위 라인업에 상보적으로 공존하던 라인업입니다. 웨스트미어-EX 기반의 제온 E7은 최대 10코어까지 탑재하고 있었습니다. (웨스트미어-EX에 관해서는 이 글에서 다루지 않겠습니다.)
샌디브릿지-EP 코어 내부를 들여다보면 MMX / SSE 이래로 가장 큰 명령어 세트 확장이라 평가받는 AVX 명령어 세트가 최초로 탑재되었고, 과거 넷버스트에 도입되었던 '트레이스 캐시'를 '마이크로옵 캐시'라는 이름으로 부활시켰는데, 이로써 사실상 L0 캐시가 신설된 것과 마찬가지의 효과를 갖게 되었습니다. 이외에도 메모리 접근 유닛의 구성이 다양해져 보다 유연하게 로드 또는 스토어 명령어를 처리할 수 있게 되었습니다.
또한 아키텍처 외적인 변화 중에서도 언코어(≒L3 캐시)와 코어가 동기화되었다는 점을 빼놓을 수 없겠습니다. 과거 네할렘 시절 2.13GHz(블룸필드)~2.66GHz(린필드)의 속도로 코어클럭보다 낮게 작동하던 언코어는 제조공정의 미세화에 힘입어 샌디브릿지부터는 코어와 같은 속도로 작동하게끔 조정되었는데, 샌디브릿지의 기본 클럭이 3.xGHz 정도에서부터 시작하는 것을 고려하면 외려 코어 부분보다도 더 큰 비율로 고속화된 것이라 할 수 있습니다. 과거 펜티엄 3 카트마이와 코퍼마인의 성능관계를 생각하면, 언코어의 고속화가 큰 성능 향상으로 연결되리라는 추측은 그리 어렵지 않습니다.
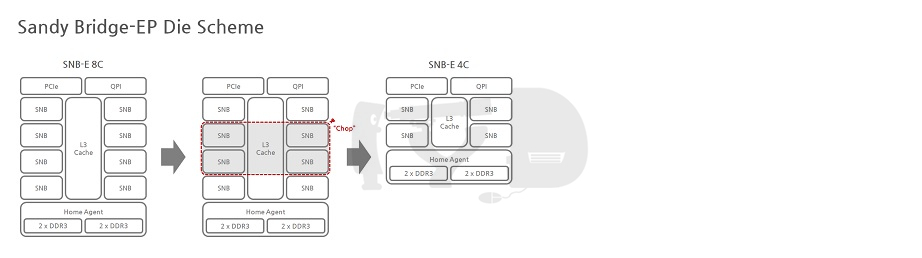
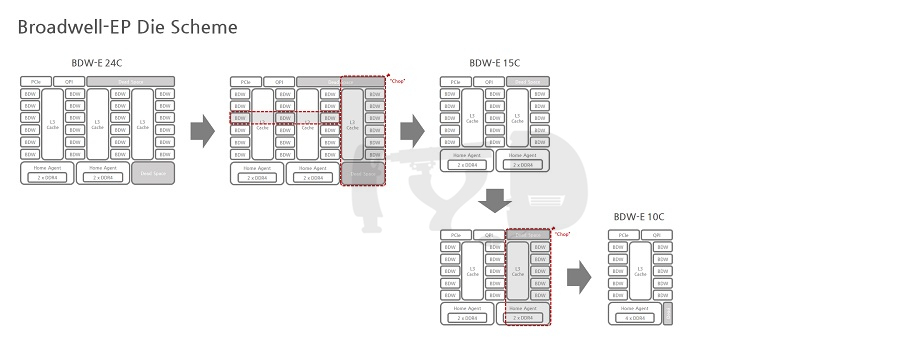
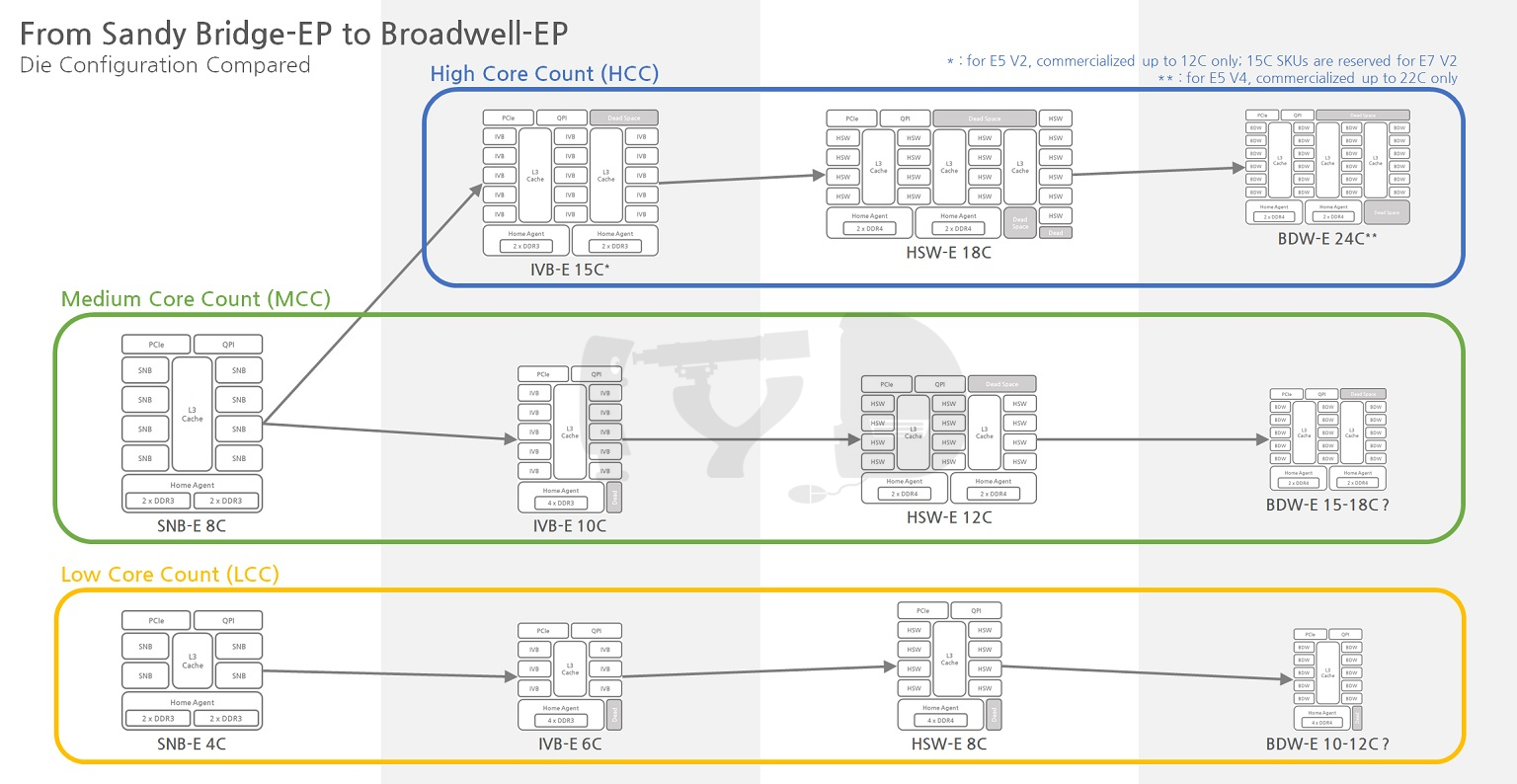
샌디브릿지 후속으로 아이비브릿지가 서버 시장에 진출하면서, 제온 라인업에 투입되는 다이는 3종으로 분화되었습니다. 얼핏 생각하면 그만큼의 리스크(생산비용 증대)를 안게 된 셈인데, 다행히 샌디브릿지부터 다이 구성방식 자체는 고도로 모듈화되어 있었기에 (가장 큰 다이인) 15코어 다이를 원형으로 하여 10코어, 6코어 다이를 아래 그림처럼 간단히 파생할 수 있었습니다.
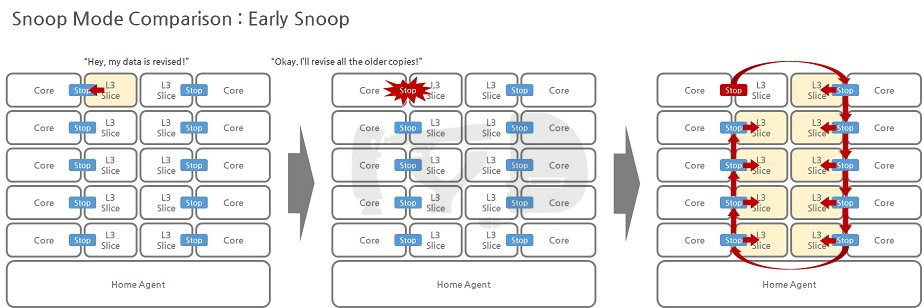
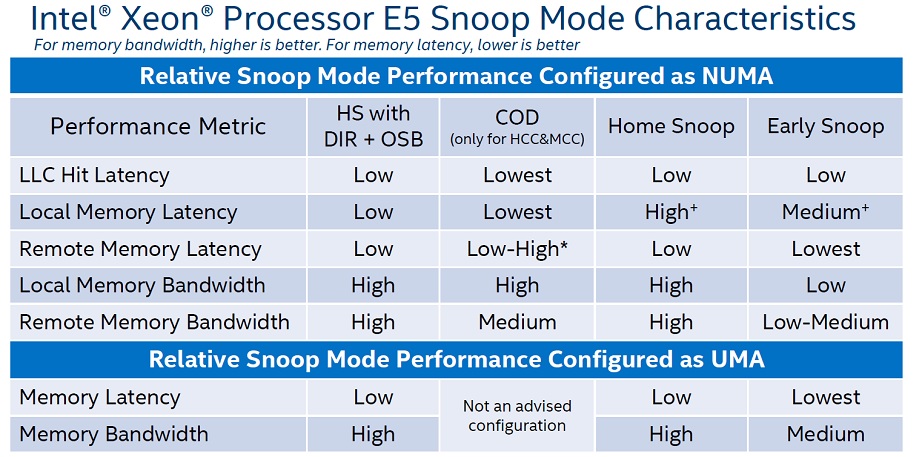
기능적으로 아이비브릿지-EP/EX가 샌디브릿지-EP와 달라진 점 중 하나는 캐시 일관성(cache coherency)을 관리하는 모드가 하나 더 추가되었단 점입니다. 캐시 일관성이란 멀티코어 시스템에서 필수적인 것으로, 여러 코어(의 캐시)에 복사되어 있는 데이터 사본들 중 어느 하나가 갱신되면 나머지 모두를 업데이트해야 함을 의미합니다. 샌디브릿지까지 기본으로 탑재하고 있던 모드는 얼리 스눕(early snoop)이라고 하는데, 각 L3 캐시에 이어진 링 정류장(Ring Stop)이 해당 캐시를 감시하며 데이터가 갱신될 때마다 링 전체에 신호를 보내 다른 캐시에 존재하는 같은 데이터의 사본을 무효화합니다.
얼리 스눕 모드 하에서는 개별 캐시에 부착된 링 정류장이 관리의 주체인 만큼, 사본이 널리 퍼져 있지 않다면 가장 적은 레이턴시로 스누핑이 가능하지만 사본이 널리 퍼진 경우엔 먼 정류장과 가까운 정류장 사이의 레이턴시가 그대로 노출될 수밖에 없는 구조이기도 합니다. 따라서 레이턴시의 변동폭이 큰 것이 약점이며, 특히 아이비브릿지-EP/EX 10코어 다이 이상을 사용한 제품은 링의 양쪽 끝에 별개의 메모리컨트롤러를 두고 있으므로 대역폭 역시 충분히 사용하지 못할 가능성이 있습니다. (한쪽 링에 속한 정류장이 다른쪽 링의 메모리컨트롤러에 접근하려면 많은 레이턴시가 소요됩니다.)
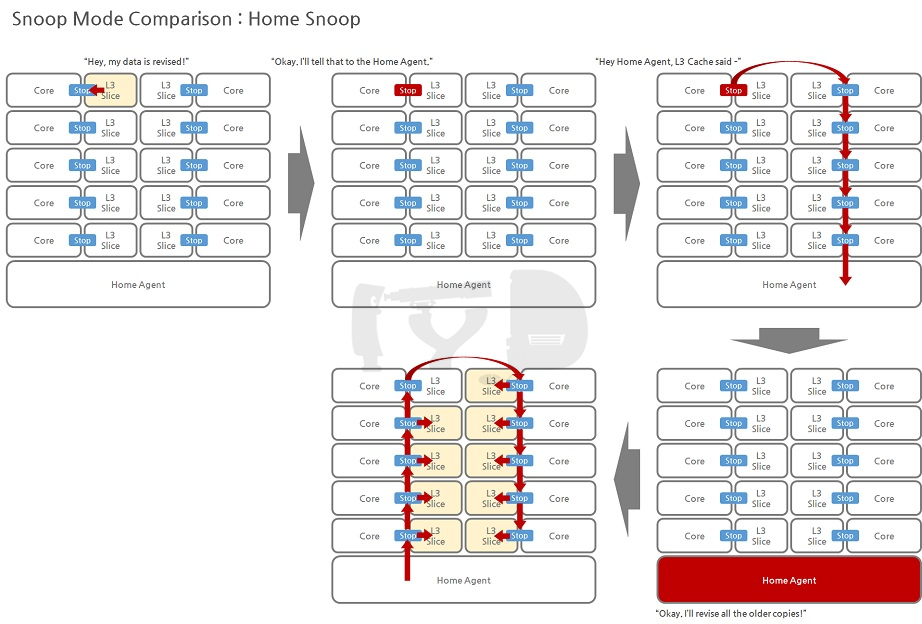
아이비브릿지-EP/EX에 추가된 홈 스눕(home snoop) 모드는 이러한 약점을 개선한 것으로 얼리 스눕과의 가장 큰 차이는 스누핑의 주체가 링 정류장에서 홈 에이전트(Home Agent)로 이관되었단 것입니다. 홈 에이전트는 종점 격으로 상대적으로 모든 링 정류장을 대칭적으로 접근할 수 있으며, 또한 두 개의 메모리컨트롤러와도 직결되므로 최대한의 대역폭을 사용하도록 도움을 줍니다. 요약하자면 비교적 일관된 레이턴시(특히 코어 갯수가 증가할수록)와 넓은 대역폭이 홈 스눕의 이점이라 할 수 있겠습니다.
3. 제온의 현대사 : 하스웰부터 브로드웰까지
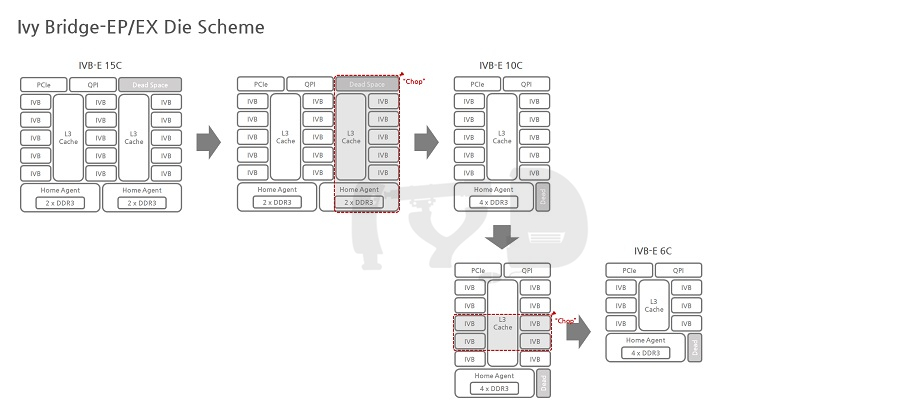
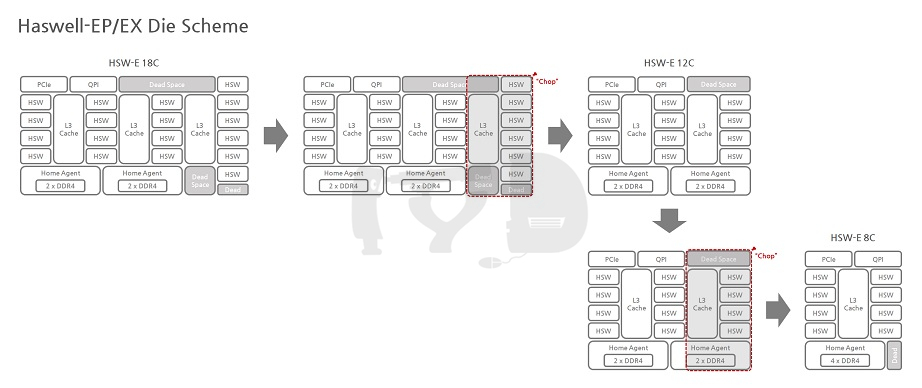
하스웰-EP/EX는 전세대와 같이 3종으로 분화된 다이를 사용하는 점은 같지만, 세부적인 구성 방식이 조금 달라졌습니다. 우선 가장 눈에 띄는 점은 각급 다이의 코어 갯수가 일제히 증가했다는 것인데요, 최하위 다이가 6코어에서 8코어로 / 중간 다이가 10코어에서 12코어로 / 최상위 다이가 15코어에서 18코어로 늘어난 점이 특징입니다.
그러나 달라진 것은 그뿐만이 아닙니다. 12코어 다이 이상급에서 홈 에이전트가 한 다이 내에서 두 개로 분리되었으며, 홈 에이전트 하나마다 물리적으로 분리된 링 버스와 메모리컨트롤러가 배치되었다는 점입니다. 어떤 의미에서는 하나의 다이로 찍어낸 멀티칩 모듈(MCM)처럼 보일 정도로까지 내부 구조가 느슨해진 것이죠. 과거 '짝퉁 듀얼코어'로 비판받았던 넷버스트 시절의 '펜티엄 D' 가 물리적으로 두 개의 실리콘을 하나의 CPU 패키지에 올린 것이라면, 12코어 다이 이상의 하스웰-EP/EX는 반대로 물리적으로 하나의 실리콘이지만 내부적으로 사실상 두 개의 CPU처럼 작동하는 셈입니다.
샌디브릿지-EP/EX에서 링 버스를 도입하며, 각 코어가 개별 L3캐시 슬라이스에 접근하는 레이턴시가 불균등해지는 새 약점이 생겼단 얘길 했습니다. 아이비브릿지-EP/EX는 여기서 코어 갯수가 더 늘어나 이 약점이 더욱 커졌지만, 그때까지만 하더라도 이로 인한 성능 손실이 눈에 띄는 정도는 아니었던 것 같습니다. 그러나 링 도메인 자체가 한 다이 내에서 두 홈 에이전트 관할로 분할되고, 각각을 접속시키기 위해 별도의 인터커넥트 스위치를 거치게 되며 링 도메인 사이를 오가는 데 소요되는 레이턴시가 급격히 늘게 됩니다. 즉, 이제부터는 성능 손실이 '눈에 띄는 정도'가 됩니다.
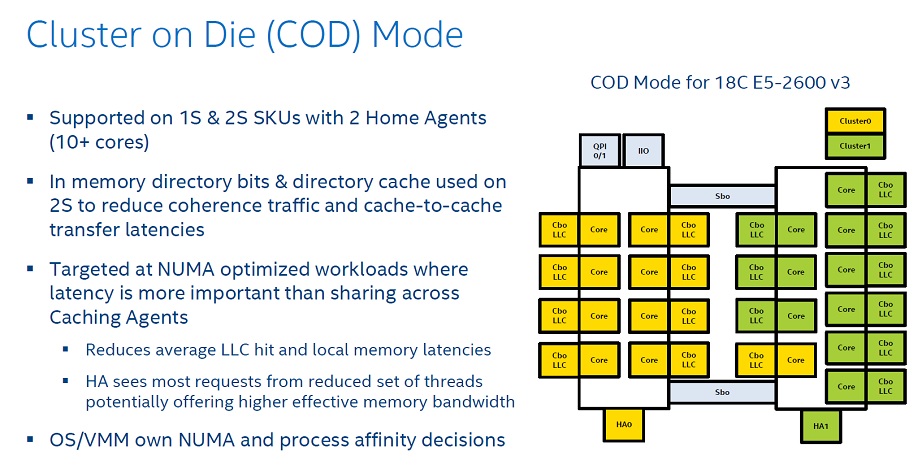
또한, 이 구조 하에서 어플리케이션이 모든 코어를 충분히 점유하지 않는 경우 (하나의 링 도메인에 속한 코어만 점유하는 경우) 다른 한쪽의 메모리컨트롤러를 사용하지 못하는 특성이 관찰되었습니다. 메모리컨트롤러가 꺼지는 문제는 당연히 인텔이 악의적으로 의도한 것은 아니겠지만, 오히려 그렇기에 더 큰 문제라고 할 수 있습니다. 다행히 이를 우회할 수 있는 옵션이 제공되어 있는데 제3의 캐시 일관성 관리 모드로써 도입된 클러스터 온 다이(COD; Cluster On Die) 모드가 그것입니다. 단, COD는 두 개 이상의 홈 에이전트를 갖는 12코어 다이 이상 제품에 한해 적용 가능합니다. 러프하게 보아 링 도메인을 기준으로, 물리적으로 한개의 다이를 논리적으로 두개의 소켓(NUMA; Non-Uniform Memory Access, 비대칭 메모리 액세스)처럼 인식하는 것입니다.
그렇잖아도 '느슨한 MCM' 같은 하스웰-EP/EX는 양쪽 링 도메인이 별개의 메모리컨트롤러를 가지게 되면서, 쿼드채널 단일소켓이라기보다는 두개의 듀얼채널 소켓에 가까운 모양이 되었고 메모리컨트롤러 성능저하 문제 역시 여기서 비롯된 것입니다. COD는 이 문제점을 맞서 해결하기보다, 아예 별도의 NUMA 도메인(별도 소켓 개념)으로 분리하여 거기서 얻을 수 있는 장점을 키우는 쪽으로 노선을 바꾼 것입니다. 한 소켓 내에 많은 코어가 있어 문제가 되니 아예 소켓을 해체해 둘로 나눈 꼴이죠.
앞서 설명했듯 COD 모드는 캐시 일관성 관리 정책의 한 가지입니다. 18코어 하스웰-EP/EX 다이 내에서 하나의 코어는 이론적으로 45MB의 L3캐시 모두에 접근할 수 있으나, 만약 필요로 하는 데이터가 다른 링 도메인에 속한 L3 캐시에 있다면 이를 액세스하기 위해 큰 레이턴시를 감수해야 합니다. 이런 사례가 빈번하게 일어난다면 전체적인 성능 저하를 피할 수 없습니다. 러프하게 보아 캐시 용량보다 속도가 중요시되는 상황이라면 성능이 떨어집니다. 반면 링 도메인을 기준으로 사실상 별개의 CPU(소켓)로 간주한다면 코어는 자신과 같은 링 도메인에 속한 L3 캐시에만 접근하게 됩니다. L3 캐시 용량이 절반이 되므로 캐시 미스는 두 배 증가하겠지만, 레이턴시가 대폭 줄어들어 최종적으로는 이득입니다.
오늘의 주인공, 브로드웰-EP의 최상위 다이는 전작 하스웰-EP/EX 최상위 다이보다 33% 증가한 24개의 코어를 탑재하고 있습니다. 그러면서도 제조공정이 미세화된 덕분에 면적은 오히려 3분의 2 수준으로 줄었는데 이는 차라리 하스웰-EP/EX 12코어 다이에 더 가까운 것입니다. 현존하는 브로드웰-EP 기반 최상위 제품인 제온 E5-2699 V4는 22코어를 탑재하고 있으며, 추후 발표될 제온 E7 V4 라인업과의 차등화 + 초창기 모델로써 안정적인 수율 확보를 위해 코어 2개를 비활성화해둔 것으로 여겨집니다.
하스웰-EP/EX와 브로드웰-EP의 다이 구조에 있어 가장 큰 차이점은 대칭성의 유무입니다. 비단 심미적으로 더 조화롭고 안정되어 보인다는 차원의 문제가 아니라 각각의 링 도메인에 할당된 코어 및 L3 캐시 슬라이스의 비대칭이 유발하는 성능상 패널티가 분명히 존재하기 때문입니다. 하스웰-EP/EX 18코어 다이는 8코어 링 도메인 + 10코어 링 도메인이 좌우로 결합한 구조로 양측 링 도메인의 코어 및 L3 캐시 슬라이스 구성이 비대칭적이기 때문에 메모리 접근이나 레이턴시 관리에 어려움이 따릅니다. 이에 비해 브로드웰-EP는 좌우 12코어 링 도메인 구성으로 대칭성을 확보했습니다.
여기에 더해 브로드웰-EP는 기존의 홈 스눕 모드에 디렉토리 캐시(DIR)와 투기형 스누핑(OSB; opportunistic snoop broadcast)을 가미해 성능을 더욱 높일 수 있는 모드를 제공하고 있습니다. 구체적으로 이들의 작동원리를 다루는 것은 이 글의 범위를 넘어서는 것이니 생략하겠지만, 성능향상을 위한 또 하나의 캐시 일관성 관리 모드가 추가된 것 정도로 이해하면 충분할 것 같습니다.
마지막으로, 인텔의 공정주기상 '틱'에 해당하는 세대교체인 만큼 브로드웰 자체는 하스웰과 큰 차이가 없으나, 파이프라인의 소폭 개량이 있었습니다. 부동소수점 곱셈 연산에 5사이클이 소요되던 하스웰과 달리 브로드웰은 3사이클만에 연산을 완료할 수 있으며, 나눗셈 역시 마찬가지의 개량이 가해졌고 이에 따라 IPC 자체가 소폭이나마 향상되었습니다.
4. 제온 E5와 E7의 차이
여기서는 1~3장에서 혼용되어 언급된 -EP와 -EX 접미사, 즉 제온 E5와 E7의 중요한 차이점 몇 가지에 대해 짧게 설명하겠습니다.
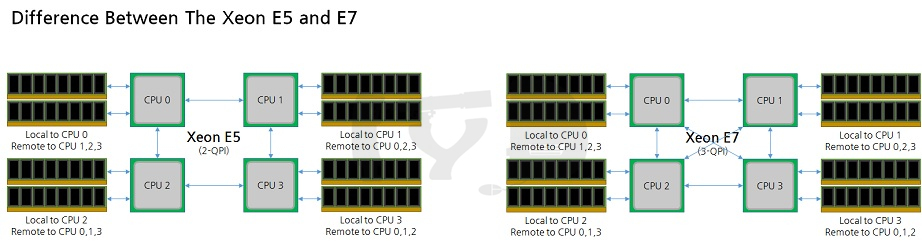
사실 제온 E5와 E7에 사용되는 다이는 같은 세대인 경우 물리적으로 완벽히 똑같습니다. 다만 제온 E5의 경우 CPU와 CPU 사이의 통신을 담당하는 QPI 유닛 하나를 비활성화해 두개인 채로 출시하는 반면 E7은 세개 모두 활성화되어 있다는 것이 하드웨어적인 차별점으로 QPI가 두개인 제온 E5는 4소켓(2^2) 구성만 가능한 반면 3개인 E7은 8소켓(2^3) 구성까지 가능합니다. 그러나 이것이 유일한 차이는 아닙니다. 똑같이 4소켓 구성일 때에도 성능상 차이가 있을 수밖에 없는데요. 아래를 살펴봅시다.
제온 E5의 경우 인접한 CPU끼리만 연결될 수 있어 전체적으로 보면 서로 직결되지 않은 CPU들이 남아 있지만, 제온 E7은 하나의 CPU가 다른 모든 CPU에 직결됩니다. 멀티소켓 시스템에서 성능을 높이는 핵심은 다른 CPU에 연결된 원격(remote) 메모리 액세스를 빨리 하는 것이니만큼, 똑같이 4소켓 구성으로 사용하더라도 제온 E7이 확실히 성능상 이점이 있습니다. 특히 메모리 대역폭이 중요한 환경이라면 이러한 차이는 극대화됩니다.
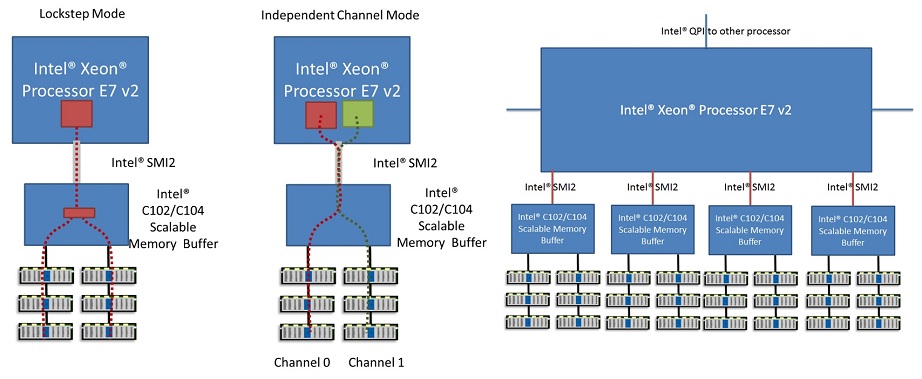
또한 제온 E7은 메모리 확장 버퍼(SMB; Scalable Memory Buffer)라 불리는 별도의 칩셋을 CPU와 메모리 사이에 배치해 제온 E5보다 메모리 인터페이스를 다양화하는 것이 가능한데, 일종의 레이드0 모드인 퍼포먼스 모드와 레이드1 모드인 록스텝 모드로 설정할 수 있습니다. 메모리 확장 버퍼를 통해 물리적으로 쿼드채널 메모리컨트롤러만을 지원하는 제온이 '논리적으로' 옥타채널까지 확장하게 되는 셈입니다.
이상으로 1~4장에 걸쳐 이어졌던 이론 설명을 마칩니다. 5장부터는 벤치마크를 통해 제온의 실전 성능을 검증해보도록 하겠습니다.
5. 테스트 준비 : 대조군 선정
실험을 통해 제대로 된 결과를 얻어내려면 정교한 설계가 선행되어야 합니다. '벤치마킹'이라는 단어가 일상어처럼 쓰이는 IT 저널리즘에서 데이터를 추출하는 행위로서의 벤치마킹은 그저 모든 절차와 사전 설계를 생략한 '기술적인 행위' 자체에 초점이 맞춰지는 경향이 있으나 이공계 학과를 전공하신 분이라면, 스스로 논문을 한 번이라도 써 본 적 있는 분들이라면 이런 접근이 얼마나 순진하고 위험한 것인지 아실 것입니다. 그렇기 때문에 많은 논문에서 '실험 재료와 방법론'(Materials and Methods)을 별개의 장으로 떼어서까지 분량을 할당하는 것이기도 합니다.
이 글 초판을 작성했던 작년 이맘때, 부끄럽게도 저는 이 부분을 전혀 숙고하지 않았습니다. 그저 기술적/기계적으로 '올바른 데이터'를 얻어 나열해 두기만 하면 그 의미는 독자들이 알아서 파악하리라 생각했죠. 그때까진 모든 리뷰가 그런 것인 줄 알았습니다. 말하자면 Raw Data에 약간의 언어적 양념만을 더해, 수많은 그래프로 도배하다시피 지면을 채워넣으면 무조건 양질의 리뷰가 된다고까지 생각했던 것 같습니다. 그러나 결과는 아시다시피 참담한 실패.
그때 저는 어떤 실수를 저질렀을까요. 가장 큰 실수는 실험 대상을 '적절하게' 좁히는 데 실패한 것이었습니다. 명인일렉트로닉스를 통해 그간 언감생심 만져보지도 못했던 CPU들이 마구 공급되니 그들 모두를 테스트해 빠짐없이 수록해내기 바빴던 것이죠. 욕심이 너무 과했습니다. 덕분에 가독성이라고는 전혀 없는, 독자 스스로는 분석을 시도조차 할 수 없는 높은 엔트로피의 거대한 그래프가 생성되고, 그것으로 끝이었습니다. 벤치마크를 통해 '이야깃거리'를 만들어내고 싶었던 제 처음의 의도 역시 깔끔히 무시되었습니다.
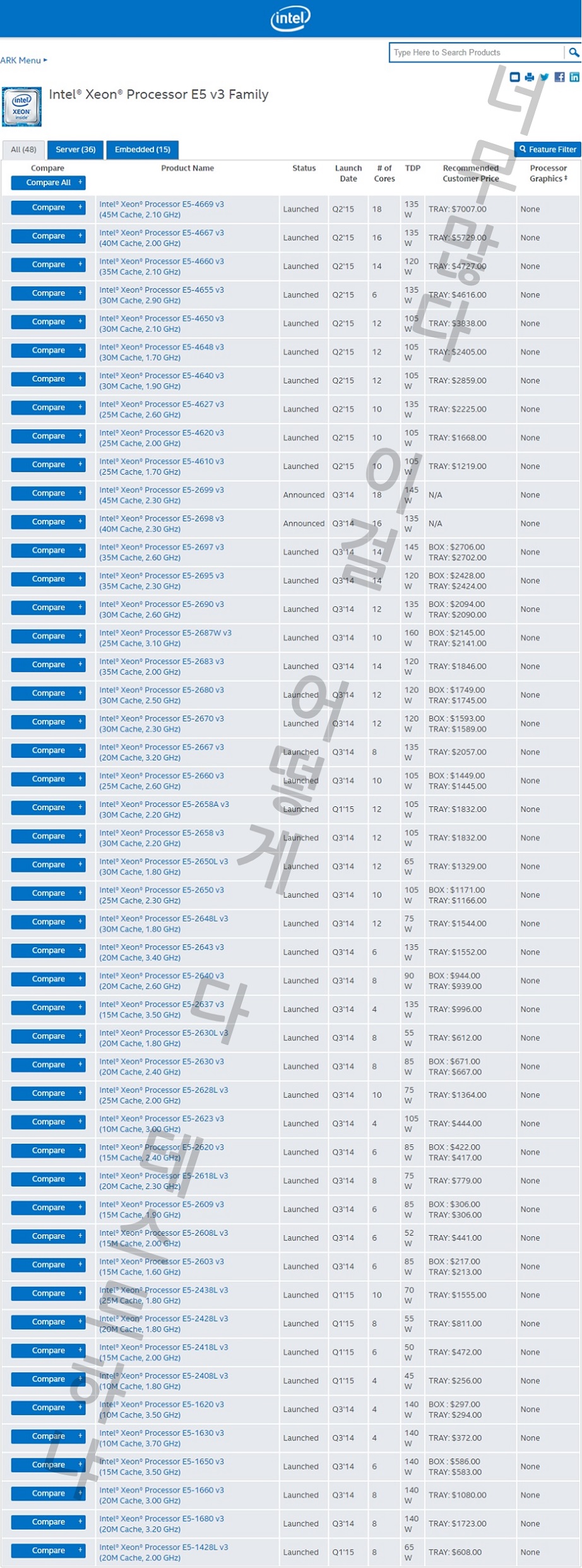
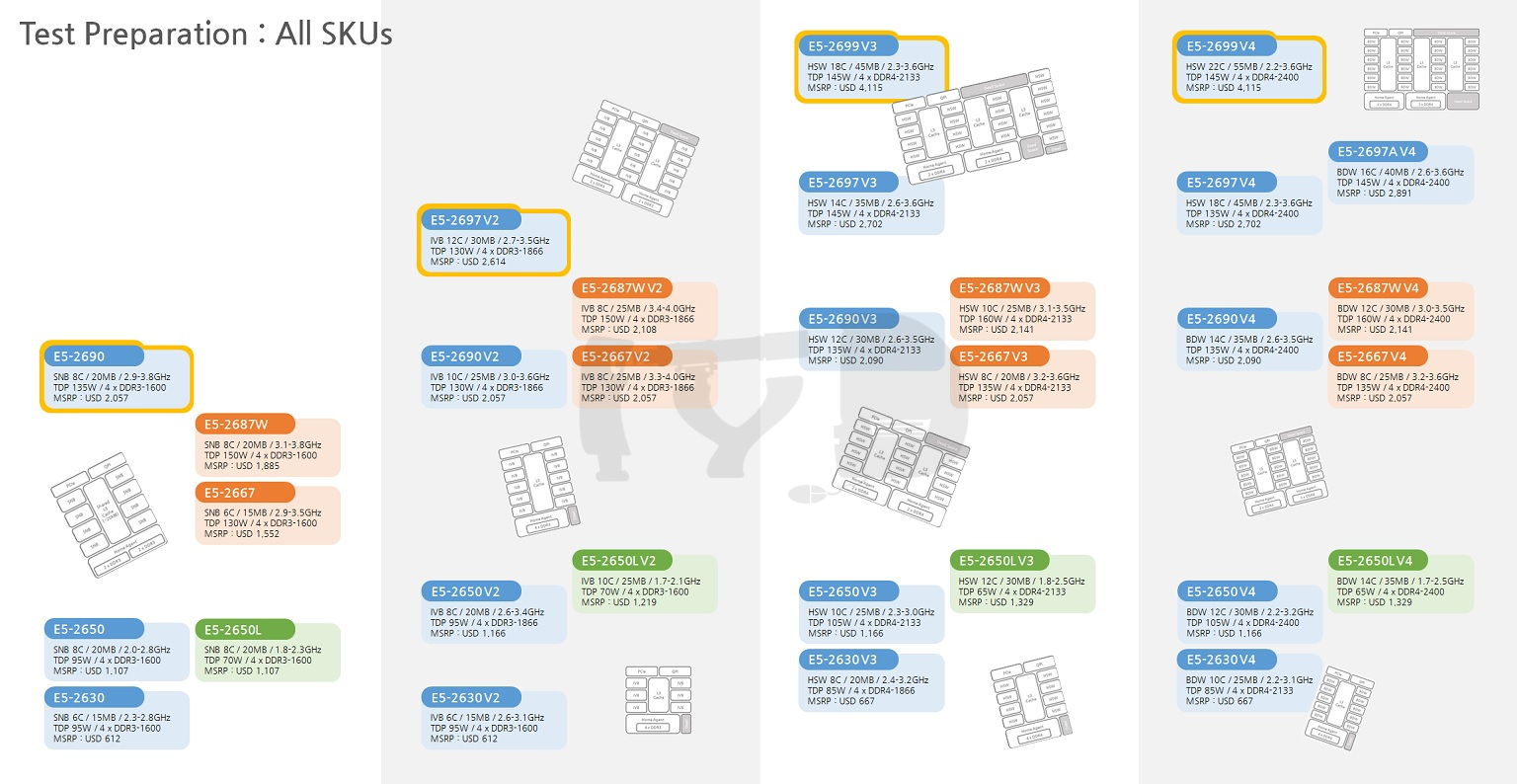
오늘날 인텔이 제공하는 제온의 라인업은 한 세대만 놓고 보더라도 무척 복잡다단합니다. 아니, 한 세대 통째로 볼 것도 없이 '제온 E5 V3' 시리즈만 해도 여기에 속한 SKU 수는 48가지나 됩니다. 이들 중 무엇을 대조군으로 선정할지가 첫번째 과제입니다. 사실상 벤치마크를 수행하기 전, 리뷰어는 이미 머릿속으로 상당한 분량의 사고실험을 선행해야 합니다. 어떤 '대표 선수'를 선정해야 선정되지 않은 나머지까지 아우르는 '대표성 있는' 결과값을 얻어낼 수 있는지 치열하게 고민해야 한단 얘깁니다.
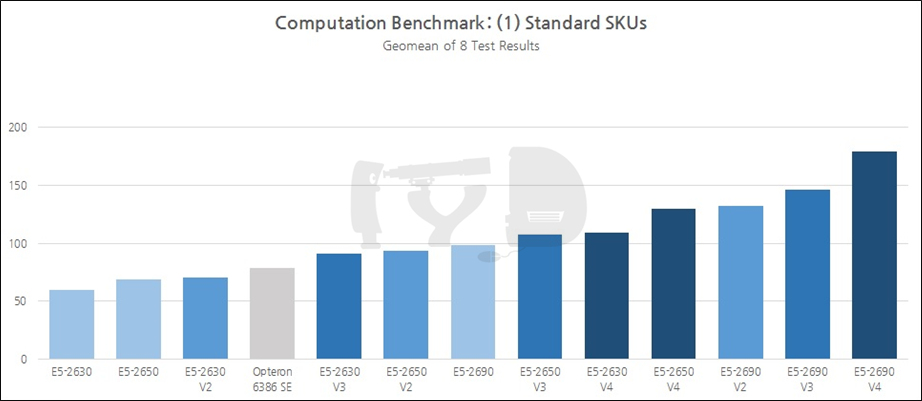
위 그림에 표시된 것이 제가 선정한 '대표 선수' 들입니다. 각 세대별로 30~40여 종에 이르는 제온 E5 2600 시리즈 SKU 중 6~9종만을 선정해, 경쟁률은 약 5:1에 달했습니다. 이 치열한 경쟁을 뚫고 선발된 친구들은 각기 어떤 특징이 있었을까요? 이를 설명하려면, 우선 제온 라인업에 대한 심도있는 이해가 필요합니다. 듀얼코어와 쿼드코어만이 존재하는 코어 i 시리즈와 달리 제온은 코어 갯수만으로 2개에서 22개까지 무려 12단계에 걸친 계층이 파생됩니다. 이들을 일괄적으로 한 줄로 세워 판매하는 것은, 예비 구매자들에게도 머리아픈 일이지만 인텔로서도 판매량을 늘리기엔 그리 좋은 전략이 못 됩니다. 대신 인텔은 '세그먼트 최적화' SKU를 도입, 워크로드의 형태에 따른 여러 특성화 모델을 공동 간판으로 내세우는 전략을 채택했습니다.
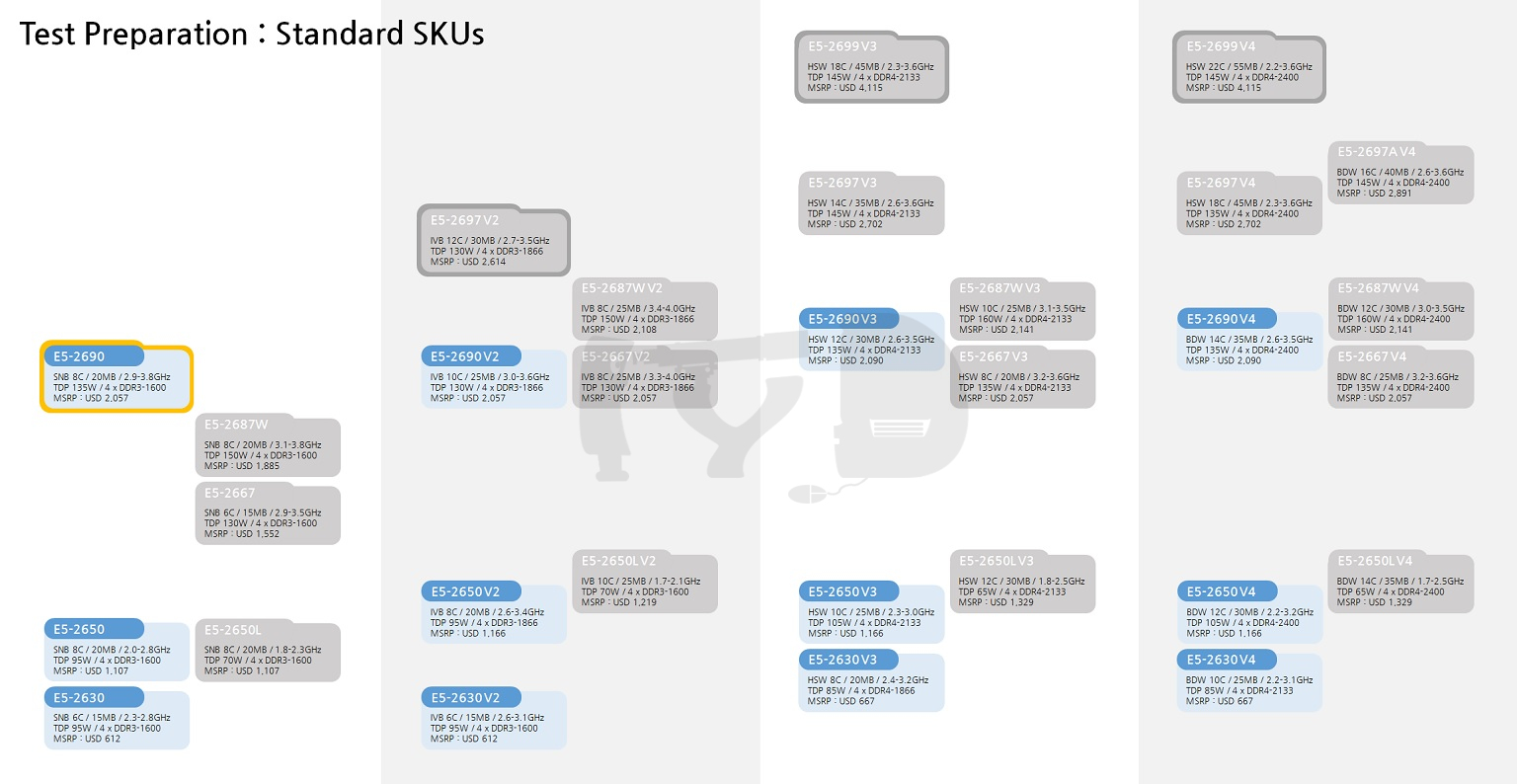
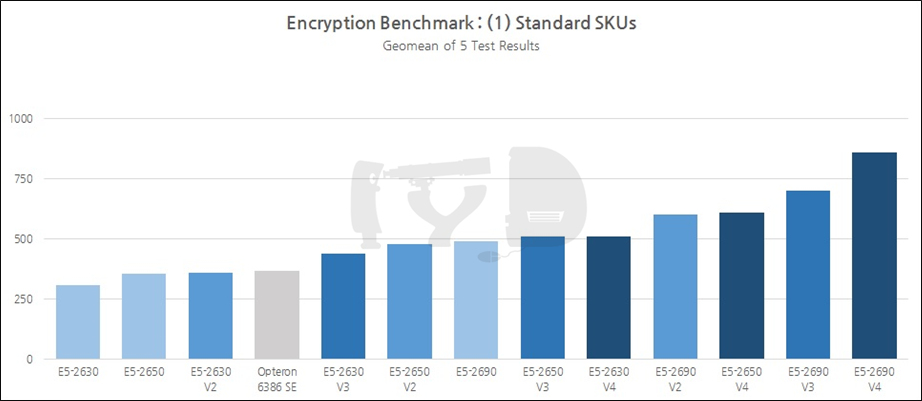
위 그림에 컬러로 표시된 모델은 일반 SKU, 즉 특정한 세그먼트에 최적화되지 않은 평범한 제온을 대표합니다. 모델넘버 끝자리가 0으로 딱 떨어지는 것이 특징인 이들은 당대의 '가장 보편적인' 코어 갯수와 작동속도를 대변하고 있습니다. 특히 각 세대별로 E5-2630과 2650은 당대의 하이엔드 데스크탑(HEDT) 라인업, 즉 코어 i7 익스트림 에디션과 밀접한 관계를 형성합니다. 2650이 가격적으로 i7 익스트림 에디션과 동등한 위치에 있다면, 2630은 하드웨어 구성이 당대의 i7 익스트림 에디션과 매우 유사하기 때문입니다. 종합적으로, 제온의 상위/중위/하위 라인업을 대표하는 '표준형'으로써 이들은 각각 상징성이 있다고 보았고, 그래서 이번 리뷰에 대조군으로 수록하게 되었습니다.
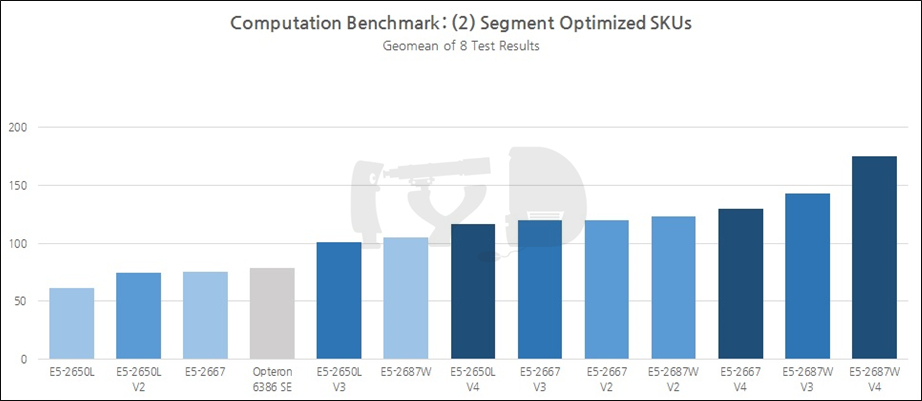
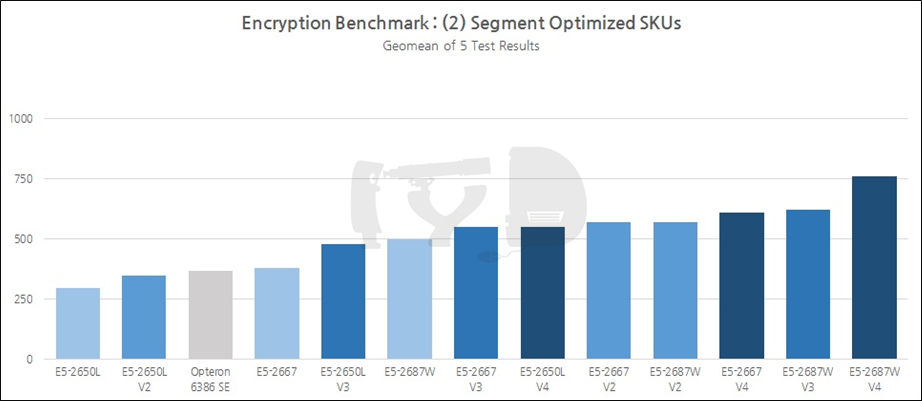
한편 일반 SKU를 제외하고도 여러 다른 대조군이 수록되었는데, 그 중 위에 표시된 것들이 바로 '특정 세그먼트 최적화' SKU입니다. 주황색은 멀티코어 성능만큼이나 싱글코어의 높은 작동속도에 초점을 맞춘 것이고, 녹색은 소비전력을 낮추는 데 집중한 것이죠. 각각 비슷한 가격대의 일반 SKU와 비교하면 '코어 수가 적고 작동속도가 높다', '코어 수가 많고 작동속도가 낮다'는 뚜렷한 특징이 있습니다. 이들 역시, 각 세대마다 딱 3개씩 존재하는 것은 아니지만 나머지들을 대변할 수 있는 대표성이 있다고 평가해 집어넣게 되었습니다. 무엇보다 각 세대로 이행하는 와중에도 변함 없이 동일한 모델넘버를 유지한 채 바통터치가 이뤄져, 세대간 추적 비교를 수행하기 좋다는 점이 가산점으로 작용했습니다.
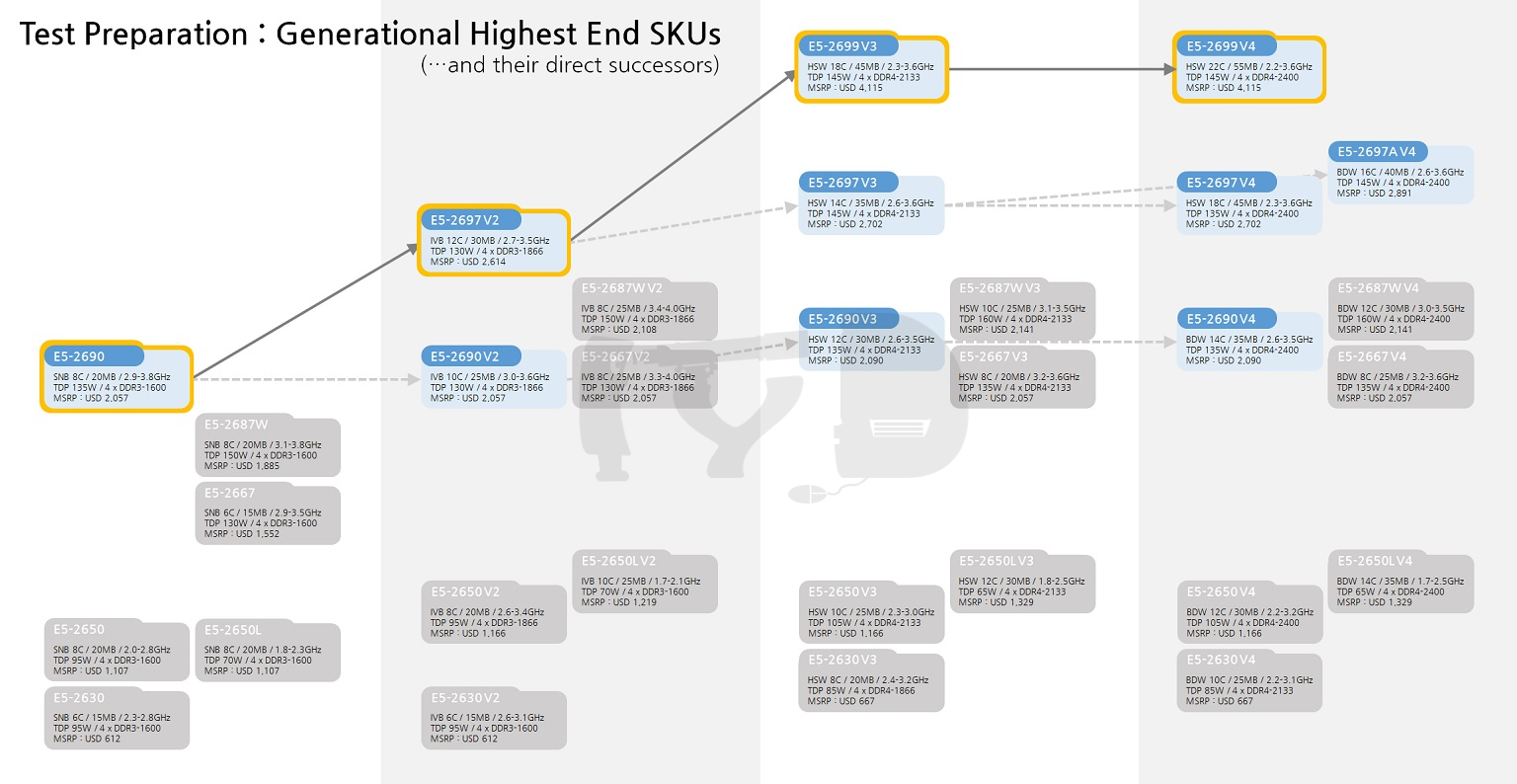
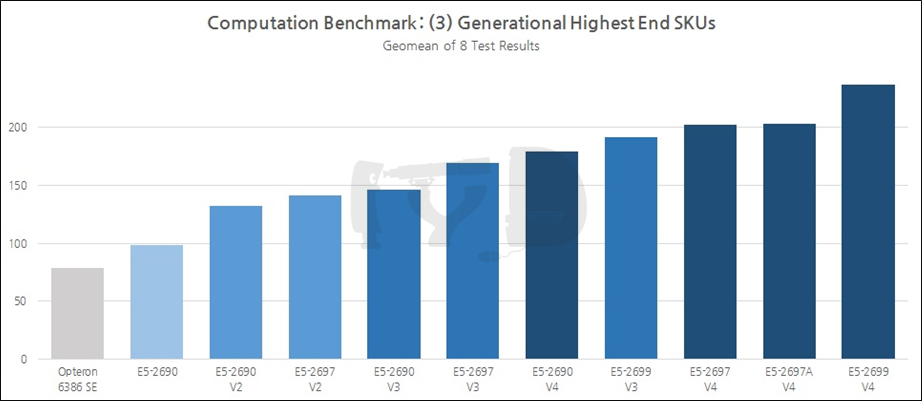
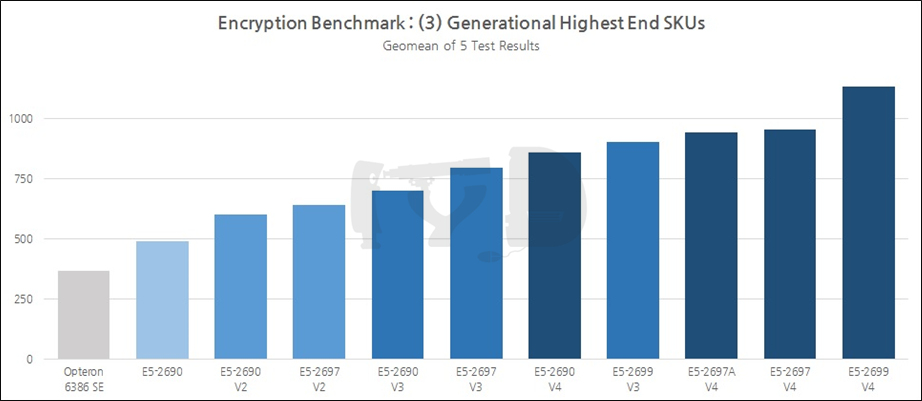
마지막으로 대조군 목록에 이름을 올린 부류는 각 세대별 최상위 SKU들입니다. 앞서 언급한 '세대간 추적 비교'와는 다른 의미에서, 각 세대별로 인텔이 당대에 집약할 수 있던 최고의 성능을 담아낸 플래그십들을 비교하는 것도 의미있을진데 보통 이들은 모델넘버가 달라지기 마련이었습니다. 예컨대 샌디브릿지 세대에서는 최상위 SKU의 모델넘버가 E5-2690이었지만 아이비브릿지 세대에서는 E5-2697이 되었죠. 좀 더 풍성한 비교를 위해, 이러한 경우 전세대 최상위 SKU에 붙여졌던 모델넘버를 승계한 후계자들도 대조군에 포함시켰습니다. 이를 통해 동일 모델넘버간 추적 비교와 함께 플래그십의 성능향상이 얼마나 급격히 이뤄졌는지를 알아볼 수 있을 것입니다.
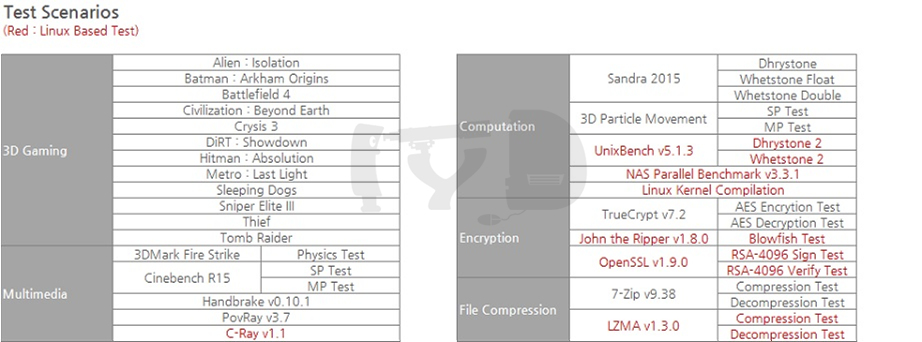
대조군이 갖춰졌으니 이들을 사용해 '무엇을 테스트할 것인가'를 결정해야 합니다. 해외의 서버 / HPC 벤치마크 사례들을 참고해 아래와 같은 벤치마크 포트폴리오를 꾸렸습니다. 그동안 거의 기계적으로 체화된 루틴(routine)의 윈도우 / 3D 게임 벤치마크에 더해, 김태현님의 도움으로 리눅스 벤치마크 항목을 거의 절반에 가까운 비중으로 집어넣은 것이 이번 포트폴리오의 특징입니다. 포트폴리오가 구성된 후엔 각 테스트 항목을 다시 성격별로 5가지 도메인으로 분류해, 성능 분석의 기초단위로 삼았습니다. 이후 이 글에서 벤치마크 결과를 언급할 때엔 '5가지 벤치마크 도메인'이 자주 언급될 것이니 숙지하시기 바랍니다.
마지막으로 방법론에 관해, 각 테스트 항목에서 얻은 점수들은 같은 벤치마크 도메인끼리 묶어 기하평균을 취해 해당 벤치마크 도메인의 성능 인덱스를 산출했고 다시 벤치마크 도메인별 성능 인덱스를 기하평균을 취해 총 성능 인덱스를 산출했습니다. 매 테스트마다 3회 반복 수행한 중위값을 해당 테스트의 대표값으로 간주했습니다.
6. 벤치마크 결과 : (1) 3D 게임 및 멀티미디어
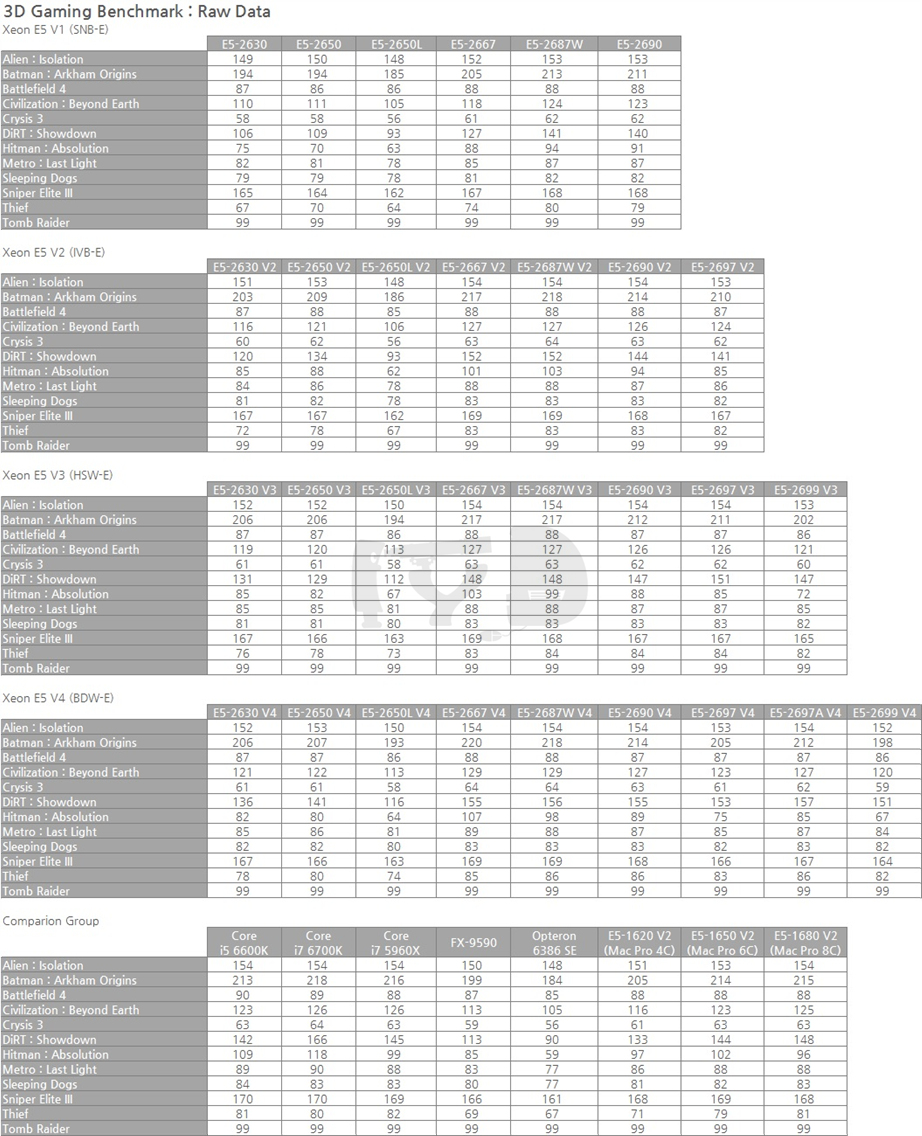
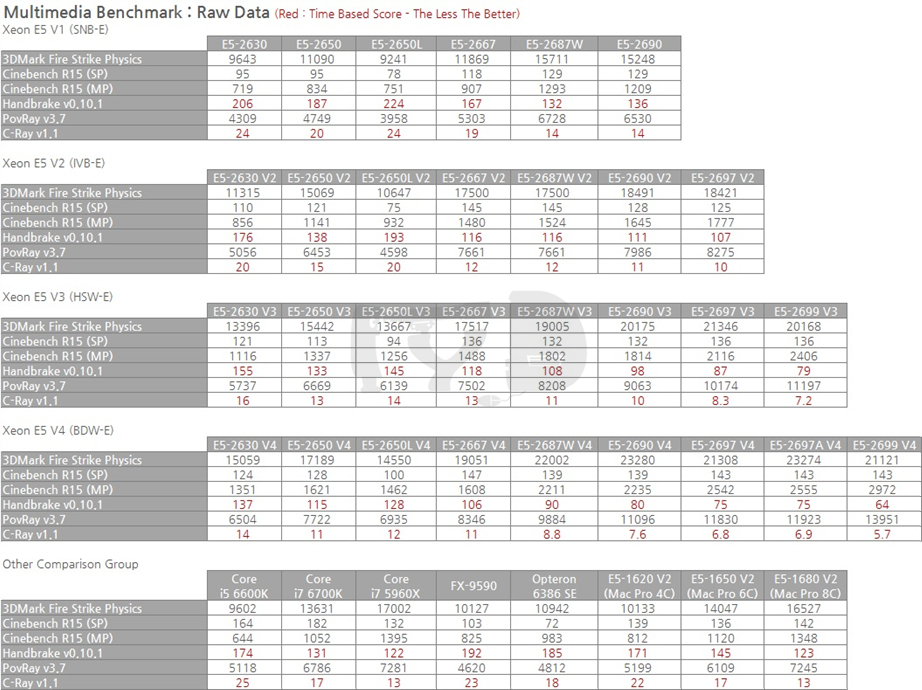
제온으로 게임하기. 많은 분들이 내심 궁금해하셨을, 그러나 차마 실행에 옮길 수는 없던 미션일 것입니다. 그래서 저희가 대신 해봤습니다. 우선 Raw Data를 간단히 수록해 두겠습니다.
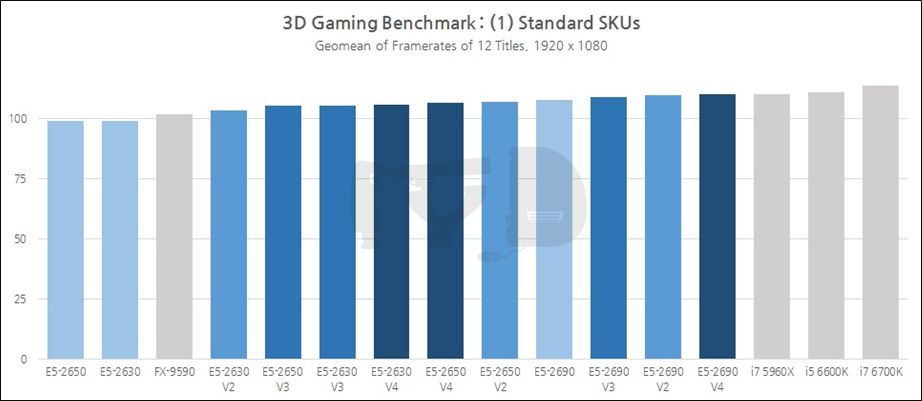
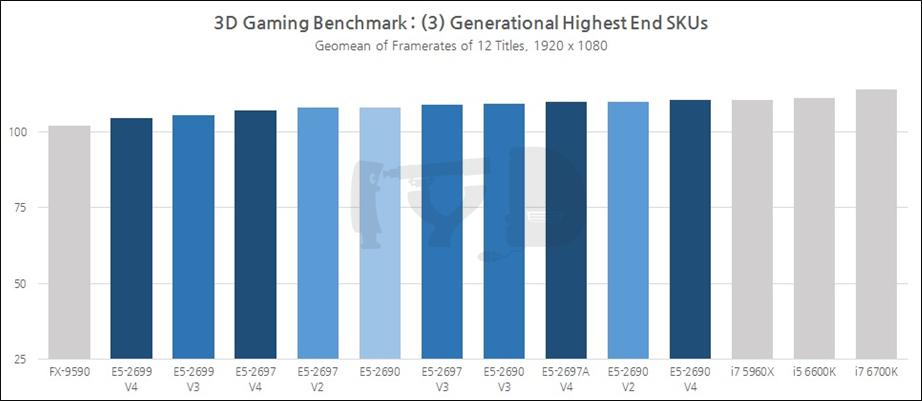
이것으로 이 장을 마치겠...다고 하면 IYD를 찾는 여러분의 발걸음도 마쳐지게 되겠죠. 다행히 저는 실패로부터 배우는 사람인지라 직관성있는 시각 자료를 함께 준비했습니다. 상술된 12종 게임 성능의 기하평균값 그래프입니다. 우선 일반 SKU 대조군부터 모아 보겠습니다.
어쩌면 많은 분들이 이미 짐작하고 있던 결과일 수도 있습니다. 반대로 제온의 코어빨을 믿던 분들이라면 다소 실망하실 수도 있겠네요. 보시다시피 어떤 제온도 평범한 인텔 데스크탑 CPU의 게임 성능을 따라잡지 못했습니다. 사실 이것은 코어 i7 5960X가 6700K보다 떨어지는 성능을 보인 것에서도 예견할 수 있었는데, 한 마디로 오늘날의 게임은 멀티코어 성능보다는 개별 코어의 고성능이 -속된 말로 코어빨보다 클럭빨이- 더 크게 작용한다고 볼 수 있습니다.
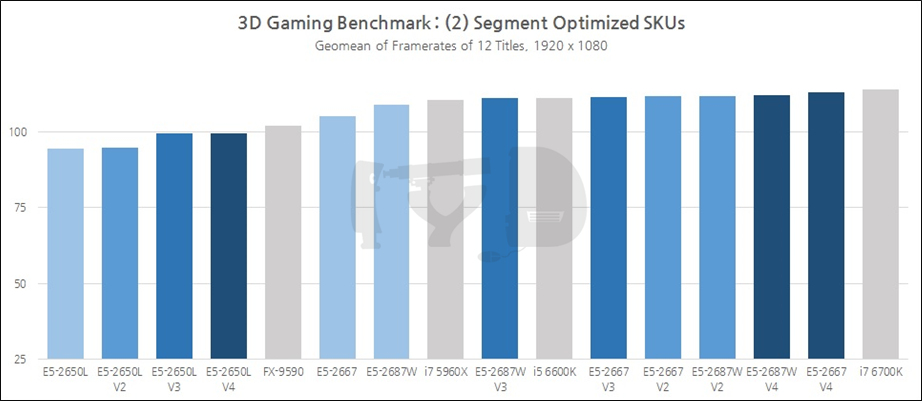
이러한 사실은 세그먼트별 최적화 SKU를 통해서도 입증됩니다. 여전히 i7 6700K가 불변의 1위를 지키고 있으나 전반적으로 제온들의 순위는, 일반 SKU들이 보이던 것보다 상향된 추세입니다. (무려 i5 6600K를 중위권으로 밀어냈습니다!) 코어 갯수는 다소 적을지라도 더 높은 작동속도에 최적화된 이들 라인업이 제대로 버프를 받은 결과입니다. 물론 저전력 최적화 SKU인 E5-2650L들은 세대를 막론하고 하위권을 벗어나지 못했는데, 이들이야말로 게임이 요구하는 덕목과는 정 반대의 특성 -많은 코어갯수, 낮은 작동속도- 을 가졌기 때문입니다.
마지막으로 각 세대별 최상위 SKU들을 모아 비교한 결과입니다. 작정하고 고클럭을 겨냥한 부류보다는 못하지만 어쨌든 전/현직 끝판왕들답게 i7 6700K를 바짝 쫓고 있는 모습이 인상적입니다. 그러나 이것도 세대 나름이라, 비교적 고클럭이던 샌디브릿지와 아이비브릿지 세대의 제온들은 좋은 성능을 보이고 있지만 기본 클럭이 각각 2.3, 2.2GHz에 불과한 하스웰/브로드웰 제온들은 하위권에 고착된 초라한 게임성능을 보여줍니다. 즉 '제온은 게임용이 아니다' 라는 명제를 상징적으로 증명해주는 장면이라 할 수 있겠습니다.
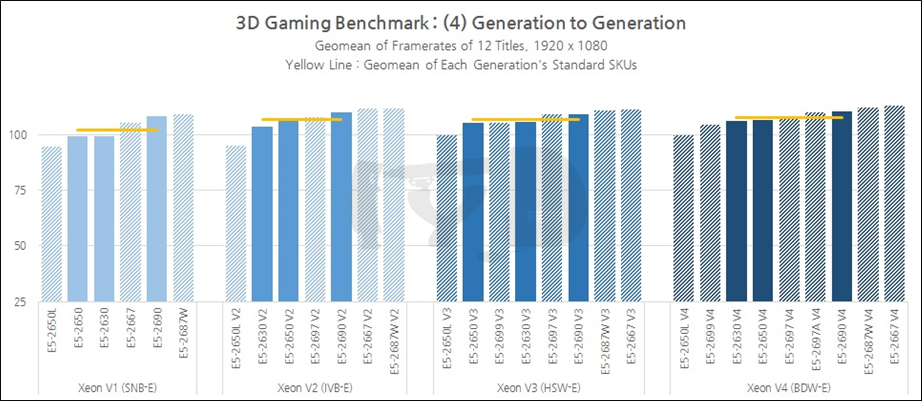
지금까지 살펴본 결과를 제온 E5 세대별로 종합한 것입니다. 4세대가 흐르는 동안 평균 게임성능은 거의 오르지 않았다고 봐도 무리가 없는데, 이것은 인텔의 아키텍처별 IPC 향상폭이 샌디브릿지 이후 그리 크지 않았던 것과도 상관이 있을 것입니다. 특히 아이비브릿지 세대에서 하스웰 세대로 넘어오면서는, 코어 갯수를 대폭 확대하는 것으로 기조가 바뀌며 반대급부로 작동속도가 일제히 낮아졌고, 따라서 평균 게임성능은 오히려 (소폭이지만) 떨어지기도 했습니다. 종합적으로 보아 게임용으로 제온을 산다거나, 나아가 3D 그래픽 점수놀이용으로도 제온은 좋은 선택이 아닙니다.
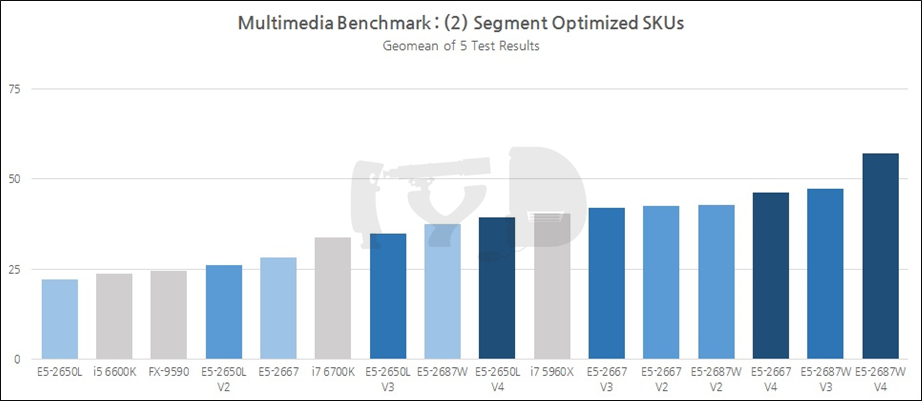
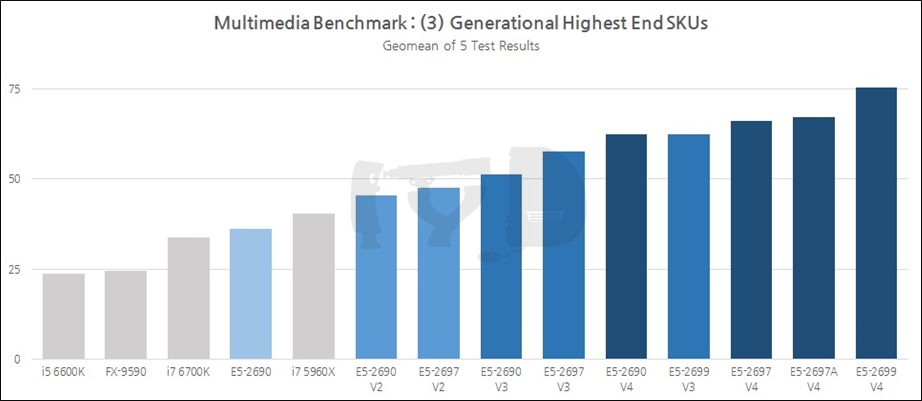
한편, 제온이 응용되는 분야 중 가장 큰 비중이 '서버'에 있다면, 그 못지않게 많은 또다른 분야는 바로 '워크스테이션'일 것입니다. 일반 중생의 입장에서야 둘 사이에 무슨 차이점이 있는지 알 바 아니겠지만 적어도 이 글을 읽으러 오신 여러분은 '일반인'의 범주에서는 훌쩍 벗어난 컴덕들 아니겠습니까. 서버가 흔히 다량의 멀티스레드 워크로드 / 많은 메모리 액세스 등으로 대표된다면 워크스테이션은 '그것보다는' 싱글코어 성능이 조금은 더 중시되는 분야라고 할 수 있겠습니다. 일반 PC와 서버의 중간적 존재랄까요. 이제 살펴볼 테스트 결과는, 이러한 워크스테이션의 워크로드 상당수를 차지할 멀티미디어 벤치마크입니다.
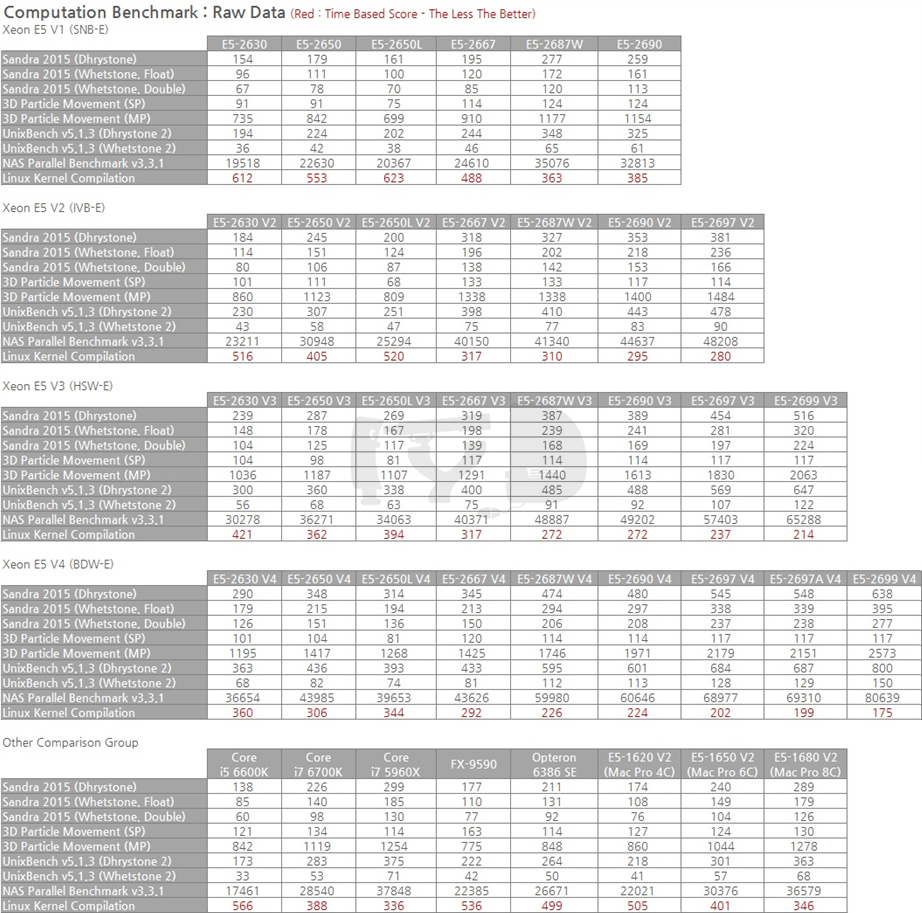
핸드브레이크 인코딩 및 C-Ray 렌더링 테스트의 결과값은 소요시간을 기록한 것으로 낮을수록 고성능을 의미합니다. 이들의 역수 및 시네벤치 SP를 제외한 나머지의 기하평균값이 이 도메인의 성능지표로써 제시되었습니다.
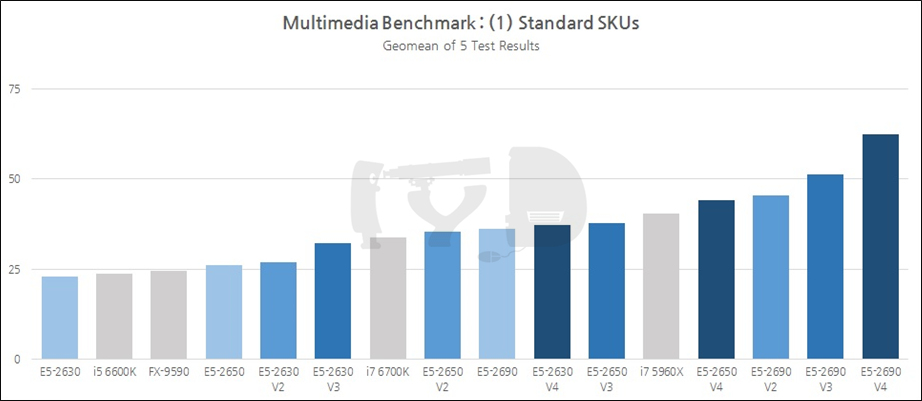
앞서 3D 게임성능 그래프를 볼 때와는 확연히 다른 추세입니다. 코어 갯수에 따른 성능 변화가 좀 더 크게 나타나 데스크탑용 CPU들의 순위가 일제히 몇 칸씩 밀렸습니다. 다만 i7 5960X와 (가격적 / 하드웨어적으로) 직접 비교 가능한 E5-2650 V3과 2630 V3은 둘 모두 i7 5960X보다 떨어지는 성능을 보이고 있습니다. 아직까지는 클럭빨이 먹히는 걸까요.
세그먼트 최적화 SKU들 역시 코어 갯수에 따른 격차가 좀 더 확연히 드러납니다. 다만 여전히 클럭은 중요한 요소로 반영되어, i7 5960X는 같은 하스웰 세대 제온인 E5-2667 V3보다 떨어지는 성능을 보였으며, 심지어 한 세대 전 SKU이지만 최대 4.0GHz까지 작동속도를 높일 수 있는 2667 V2에게도 뒤처지는 모습을 보였습니다.
마지막으로 각 세대별 최상위 SKU를 모은 결과입니다. 실로 놀랍습니다. 코어 갯수가 상대적으로 적은 세그먼트 최적화 SKU 그래프는 말할 것도 없고, 일반 SKU 그래프에서 최상위권을 차지했던 2690들이 처참히 나가떨어진 것에서부터 '큰 형님들'의 위력이 실감납니다. 데스크탑용 CPU들은 감히 명함도 내밀 수 없겠습니다.
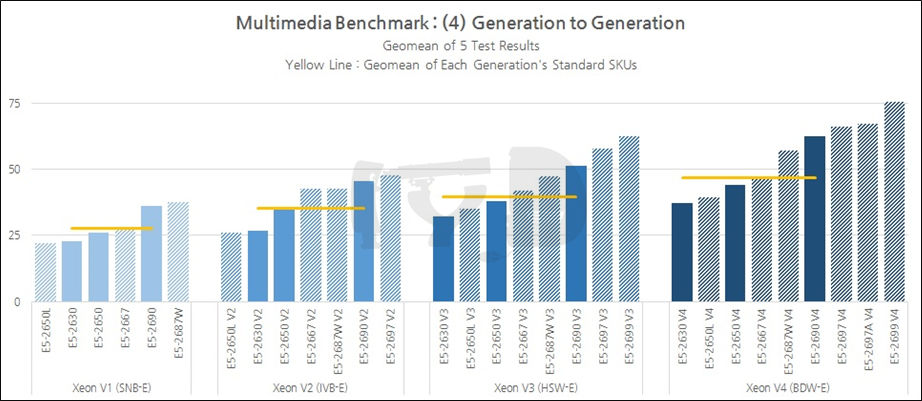
지금까지 살펴본 결과를 제온 E5 세대별로 종합한 것입니다. 4세대에 걸친 누적 성능향상폭은 68%로 각 세대마다 평균 20% 안팎의 성능향상을 이뤘다고 볼 수 있습니다. 가장 성능향상이 컸던 세대교체는 샌디브릿지에서 아이비브릿지로 넘어갈 때였고(26%), 가장 낮은 것은 아이비브릿지에서 하스웰로 넘어갈 때였습니다(11%). 이번에 브로드웰-EP가 출시되며 단행된 세대교체에서는 18%의 성능향상이 일어나 전세대보다 더 큰 업그레이드가 될 것으로 보입니다. 하스웰은 '톡'이었음에도 불구하고 제온 라인업에서 그리 임팩트있는 한 방을 못 보여줬습니다.
7. 벤치마크 결과 : (2) 연산성능, 암호화 및 파일 압축
앞 장의 두 벤치마크 도메인이 각각 '일반 PC'와 '워크스테이션' -PC와 서버의 중간적 존재로서의- 을 대표했다면, 이 장에서 소개할 나머지 벤치마크 도메인은 전형적인 '서버' 또는 '고성능 컴퓨팅'(HPC) 영역의 그것입니다. 특히 이 장에서는 리눅스 벤치마크의 비중이 높아지는데, 이러한 결과들이 정통 서버 영역에서 어떻게 작용할지 - 나아가 메인프레임 시장에 진출해 있는 제온 E5의 친형 E7이 리눅스/유닉스 환경에서 어떤 퍼포먼스를 발휘하는지에 대한 간접 경험으로 쓰일 수 있으면 좋겠습니다.
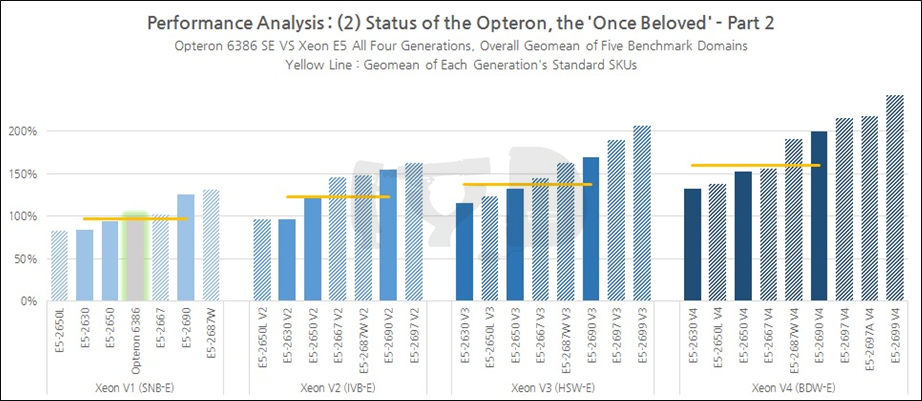
앞 장에서 약방의 감초로 활약한 데스크탑 CPU들이 퇴장하고, 이 장에서는 제온의 오랜 숙적 옵테론이 카운터파트로 출연하게 되었습니다. 파일드라이버 아키텍처 기반의 '아부다비' 다이를 사용한 옵테론 6386 SE가 바로 그것입니다. AMD가 파일드라이버 이후 하이엔드 데스크탑 / 서버 시장의 업데이트를 전혀 하지 않아 출시된 지 이미 4년이 지난 옵테론 6386 SE는 여전히 AMD의 라인업 최상단을 지키고 있습니다. 과연 이 친구가 오늘날의 젊은 제온들을 만나 얼마나 힘을 쓸 수 있을지 살펴봅시다.
재미있는 것은 E5-2650 V4와 2630 V4의 결과입니다. 전자는 1~2세대 전의 최상위 일반 SKU이던 2690 V2/V3을 거의 근접한 수준으로 따라잡고 있으며 후자는 전세대 상위 SKU인 2650 V3을 엇비슷하게 넘어서는 결과를 보였습니다. 세대교체를 통해 성능-가격 곡선이 점차 우하향하게 된다는 사실을 시각적으로 드러낸 극명한 예입니다.
세그먼트 최적화 SKU 중에서는 E5-2687W V4가 가장 좋은 성능을 보였으며, 같은 세대 하위 SKU인 2667 V4 대신 전세대 동일 모델넘버 SKU인 2687W V3이 그 뒤를 이었습니다. 앞 장에서 살펴본 세대간 성능격차를 생각하면 잘 이해되지 않을 수 있는 결과로, 이것은 2687W와 2667이 상징하는 세그먼트의 미묘한 차이 때문입니다.
둘 모두 고클럭화를 중시하는 '프리퀀시 옵티마이즈드' 세그먼트에 속하지만 고클럭화와 다(多)코어화를 병행 추진하는 2687W와 달리, 2667은 외곬수로 고클럭화에만 올인하는 모양에 가깝습니다. 심지어 최상위 다이의 코어 갯수가 24개로 늘어난 브로드웰 세대에서마저 2667 V4는 8코어에 그치고 있습니다. 이러한 설계철학의 차이(?) 탓에 2687W와 2667은 비록 모델넘버로는 상/하관계처럼 보이나, 사실상 동등한 '투 톱'으로 프리퀀시 옵티마이즈드 세그먼트를 이끌고 있습니다. (실제로 둘의 가격은 거의 엇비슷합니다.)
최상위 SKU끼리의 비교 그래프에서 옵테론은 완전히 압살당했습니다. 여기서 주목할 것은 E5-2697 V4와 2697A V4 쌍둥이의 성능입니다. 전자는 18코어 / 2.3GHz, 후자는 16코어 / 2.6GHz의 사양을 갖췄으며 왜 인텔이 굳이 그렇게 했는지는 모르겠으나, 어쨌든 같은 모델넘버를 부여받은 형제답게 매우 비슷한 성능을 보였습니다. 아마 16~18코어 언저리에서 브로드웰-EP의 수율이 극명히 갈리는 '특이점'이 도래했고, 이에 따라 인텔이 '아깝게 2697 V4가 되지 못한' 다이를 구제하기 위해 해당 SKU를 긴급 신설한 것으로 상상해볼 수 있을 것 같습니다.
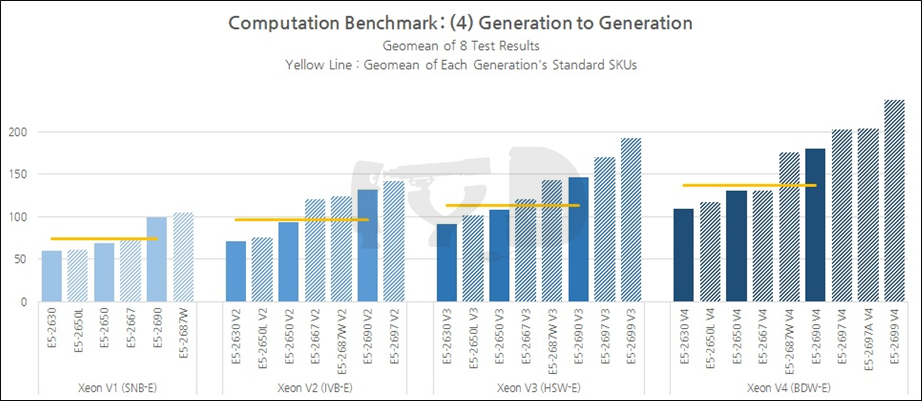
지금까지 살펴본 결과를 세대별로 종합해 보면 4세대에 걸친 성능향상폭(샌디브릿지 -> 브로드웰)은 무려 84%를 넘었습니다. 이번에도 아이비브릿지에서 하스웰로 세대교체될 때의 성능향상폭이 가장 작았고(17%) 샌디브릿지에서 아이비브릿지로 넘어갈 때가 가장 컸으며(29%) 하스웰에서 브로드웰로 넘어갈 때의 성능향상폭은 그 중간쯤이었습니다(21%). 물론 이것만으로 하스웰-EP 기반 제온 E5 V3가 망작이었다고 폄하할 수는 없고, 위 그래프에서 평균값을 취한 대상이 일반 SKU 한정이었음을 생각하면 최상위 SKU를 반영하면 결과가 달라질 수 있단 점 염두에 두시기 바랍니다. 단지 동일한 모델넘버를 추적 비교했을 때의 추세가 그러하단 것입니다.
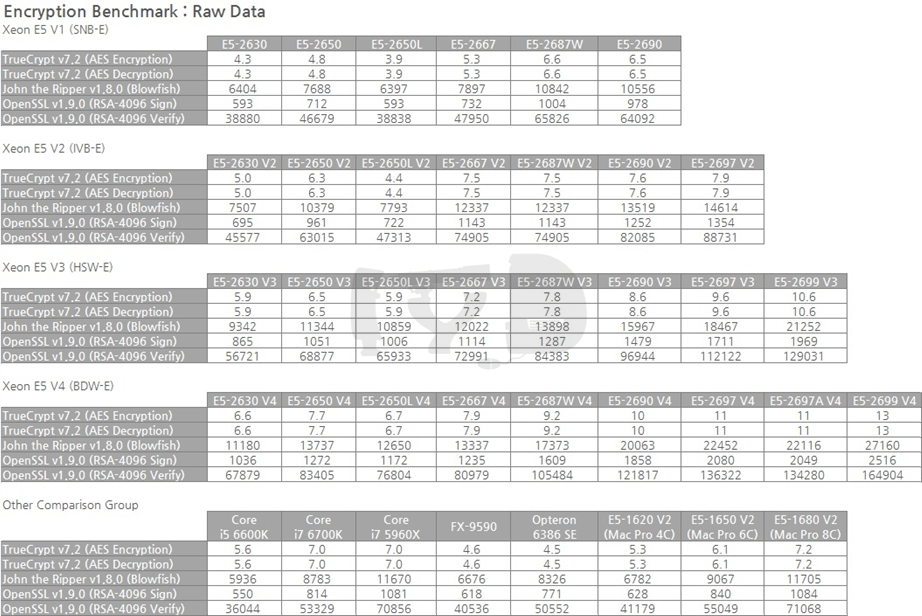
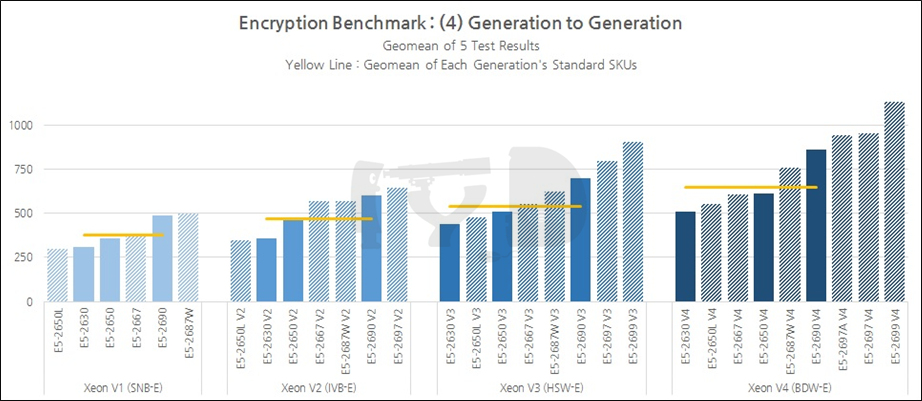
이번에는 암호화 벤치마크 결과를 살펴보겠습니다. 연산성능 자체만큼이나 암호화 성능은 서버에서 중요시되는 덕목으로, 아무리 적은 규모의 서버에서도 암호화/복호화 쿼리는 하루에도 수천 번씩 일어나는 것이 다반사이기 때문입니다. 인텔은 샌디브릿지부터 / AMD는 불도저부터 각각 암호화에 특화된 별도의 명령어 세트를 탑재하게 되었을 만큼 이 분야는 제조사들이 공들여 다듬고 있는 분야이기도 합니다.
이 부문의 테스트 항목 중 TrueCrypt를 제외한 나머지 둘은 리눅스 하에서 테스트되었습니다. Raw Data를 늘어놓고 보는 건 아무래도 의미가 없으니 그래프를 봅시다.
앞서 살펴본 연산성능 벤치마크와 비슷한 양상을 보이고 있습니다. 옵테론 6386 SE 밑에는 E5-2650, 2630과 2630 V2가 깔려 있는데 여기서 중요한 것은 2650과의 성능관계입니다. 일반 SKU 중에서도 전체 라인업의 허리에 해당하는 -50 모델넘버는 당대 제온의 표준형을 대변하는 것입니다. 파일드라이버가 샌디브릿지-EP의 집권기인 2011~2012년에 등장했음을 생각하면 실제로 그때까지만 하더라도 옵테론은 당대의 제온과 직접적인 경쟁이 가능했을 것으로 보입니다. 물론 이후 비약적으로 성능을 높이며 멀찌감치 달아난 아이비브릿지-EP/EX부터는 다시는 대등한 경쟁을 펼치지 못했습니다.
이번에는 저전력 특화 SKU 이야기를 해 봅시다. 최하위권을 지키고 있는 E5-2650L, 2650L V2와 달리 하스웰 세대부터는 꽤 순위를 높이고 있는 것을 볼 수 있죠. 이것은 샌디브릿지 세대까지만 하더라도 제온용 다이가 한정적이었던 것과 무관치 않습니다. 사실상 8코어 다이 하나뿐인 상황에 저전력을 추구하자면 작동 속도를 대폭 낮추는 것 외엔 선택지가 없었기 때문인데요.
이후 하스웰-EP/EX부터 중급 다이의 코어 수도 12개를 넘게 되었고, 이에 따라 작동 속도를 대폭 낮추더라도 반대급부로 많은 코어를 탑재할 수 있게 되어 성능이 개선된 것입니다. 브로드웰-EP 기반 E5-2650L V4는 무려 14개의 코어를 탑재하고 있어, 1000달러 초반에 구할 수 있는 가장 '머릿수 많은' SKU라는 기록도 세웠습니다.
마지막으로 최상위 SKU 그래프입니다. 우선 E5-2697 V4 / 2697A V4 쌍둥이를 볼까요. 그동안은 엇비슷하거나 미세하게나마 2697A V4쪽이 더 성능이 좋았지만, 여기서는 2697 V4의 성능이 -여전히 미세하기는 하나- 눈에 보일 정도의 차이로 더 좋습니다. 암호화라는 분야의 특성상 멀티스레드 성능이 절대적으로 요구되기 때문인 것으로 보입니다. 이 둘은 모두 전세대 플래그십인 2699 V3보다 좋은 성능을 보이고 있어 격세지감을 느끼게 합니다. 18코어 / 2.3GHz인 2699 V3의 가격은 4115 달러, 똑같은 코어 수 / 작동속도를 갖춘 2697 V4의 가격은 2702 달러입니다.
지금까지 살펴본 결과들이 하나같이 '멀티스레드 성능'에의 편중을 가리키던 것과 사뭇 달리, 세대간 비교에서는 1~4세대 누적 평균성능 향상폭이 71%에 그쳐 앞서 살펴본 연산성능 벤치마크에 못 미쳤습니다. 나름대로 해석하자면 멀티스레드에는 의존하나, 각 아키텍처간의 IPC에는 그다지 의존하지 않는다고도 해석할 수 있겠습니다.
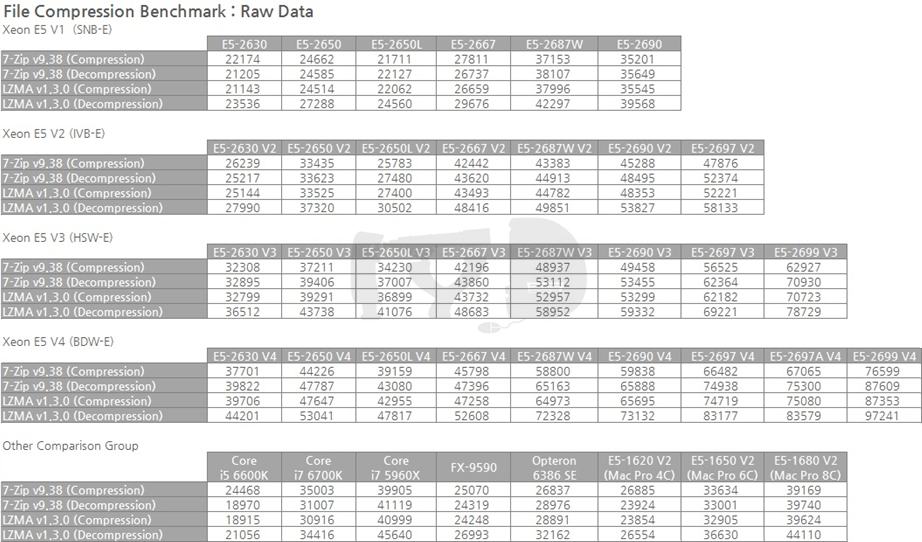
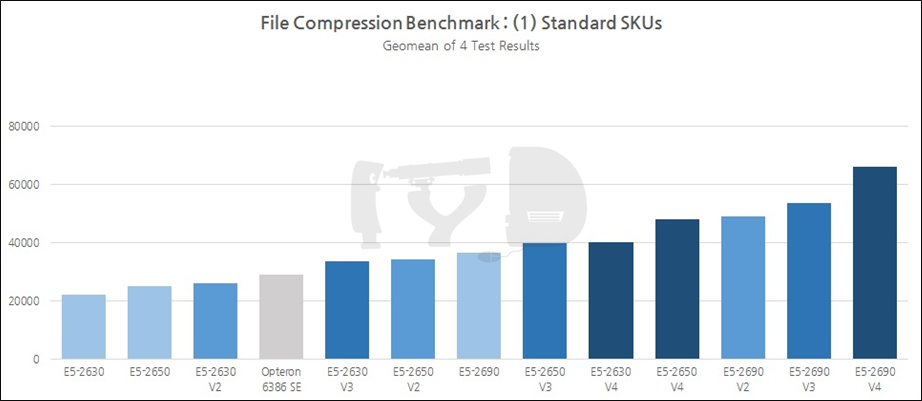
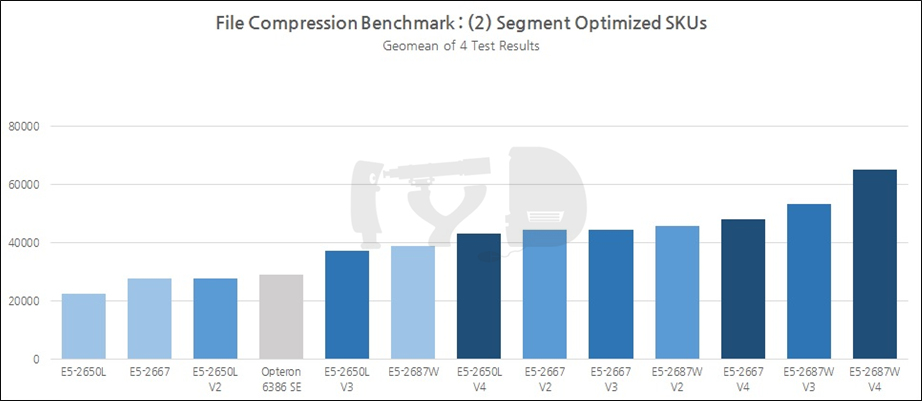
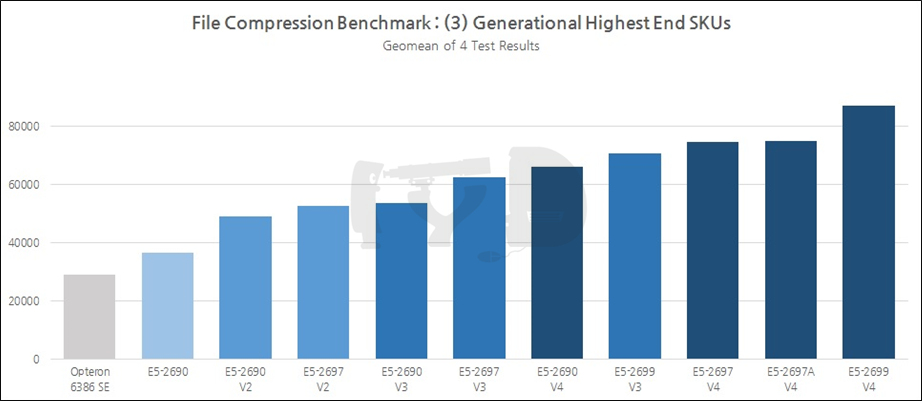
이 장 마지막으로 살펴볼 벤치마크 도메인은 바로 파일 압축입니다. 거두절미하고 Raw Data부터 보여 드립니다.
짐작하시겠지만 7-Zip은 윈도우에서, LZMA는 리눅스 하에서 테스트된 것입니다. Raw Data를 스캔하면 자동으로 머릿속에 그래프가 그려지는 분이시라면 상관없지만, 저는 이 글을 쓰고 있는 저와 보고 계신 여러분 모두 그런 부류가 아니란 사실을 잘 압니다. 그래프를 봅시다.
이 장에서 살펴본 다른 두 벤치마크 도메인의 결과와 유사한 트렌드를 보이고 있습니다. 역시 눈여겨볼 것은 왕년에 잘 나갔던 옵테론, 그리고 그야말로 압도적인 성능향상을 이뤄낸 2690 V4, 그에 비해 전세대 대비 성능향상폭이 초라한 2690 V3. 이제 다음 그래프로 넘어갑시다.
여기서는 E5-2667이 옵테론보다 아래로 내려온 것은 물론, 2650L V2보다도 아래에 놓였습니다. 앞선 벤치마크 도메인들보다도 더욱 멀티스레드 성능이 중시되었다고밖에는 해석할 수 없겠네요.
여기서는 여전히 E5-2697 V4와 2697A V4가 엇비슷한 성능을 보이고 있으며, 둘 모두 2699 V3보다는 확실히 성능이 좋고, 따라서 브로드웰-EP 기반 제온 E5 V4의 가성비는 엄청나게 향상된 것이다 - 라는 결론을 도출해 냅니다. 심지어 2690 V4마저 30% 이상 비싼 2697 V3보다 성능이 좋습니다.
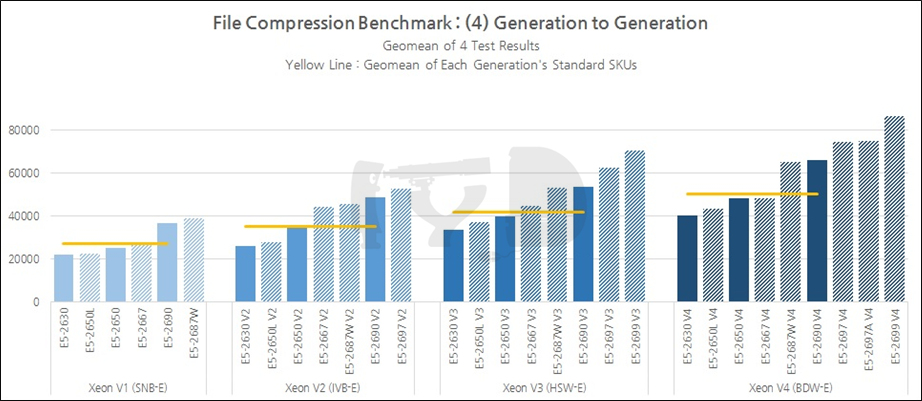
지금까지 살펴본 결과를 세대별로 종합해 보면, 일반 SKU의 성능지표 기하평균값은 1~4세대에 걸쳐 무려 85%에 육박해 다른 모든 벤치마크 도메인을 뛰어넘었습니다. 멀티스레드 성능만큼이나 아키텍처간 IPC 차이도 잘 반영되었다고 볼 수 있겠죠. 샌디브릿지에서 아이비브릿지 세대로 옮겨갈 때는 29%, 아이비브릿지에서 하스웰 세대로는 17%, 하스웰에서 브로드웰 세대로는 21%의 성능향상이 있었습니다.
8. 벤치마크 결과 : (3) 스눕 모드별 성능 비교
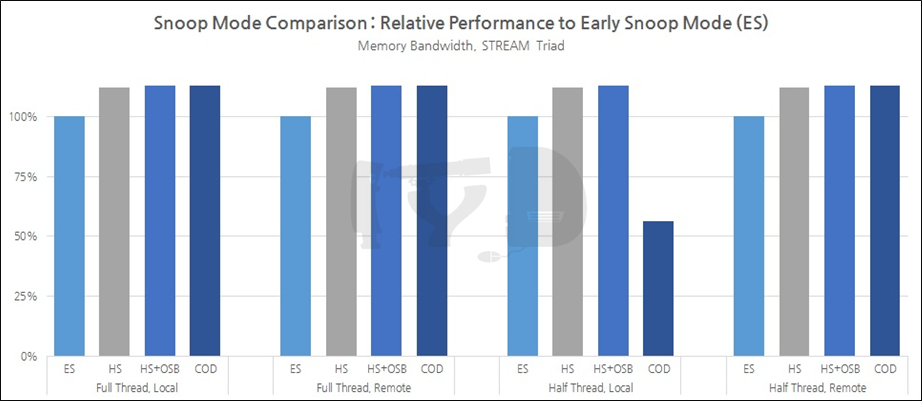
3장에서는 하스웰-EP/EX와 브로드웰-EP에서 새로 도입된 두 가지 캐시 일관성 관리 모드, COD와 OSB에 대해 간단히 짚고 넘어갔었습니다. 2장에서는 샌디브릿지-EP와 아이비브릿지-EP/EX에서 도입되었던 얼리 스눕과 홈 스눕에 대해 살펴보았죠. 이론적으로만 살펴본 이들의 실제 성능을 공개합니다.
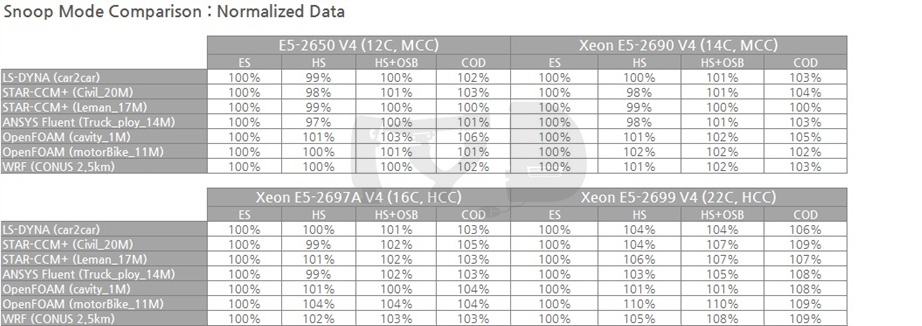
우선 네 가지 스눕 모드를 모두 활용할 수 있는 대조군이어야 했기에 테스트 대상은 제온 E5 V4로 자연스레 좁혀졌습니다. 또한 COD가 적용 가능하려면 두 개의 홈 에이전트가 각각의 링 도메인을 관할하는 다이 구조를 가져야 하는데, 브로드웰-EP애서 이러한 다이 구조를 갖는 것은 12코어 이상 모델로 한정됩니다. 오늘의 대조군들 중 이 조건을 충족하는 것은 E5-2650 V4, 2690 V4, 2697 V4, 2697A V4, 2699 V4의 다섯 종으로 좁혀집니다.
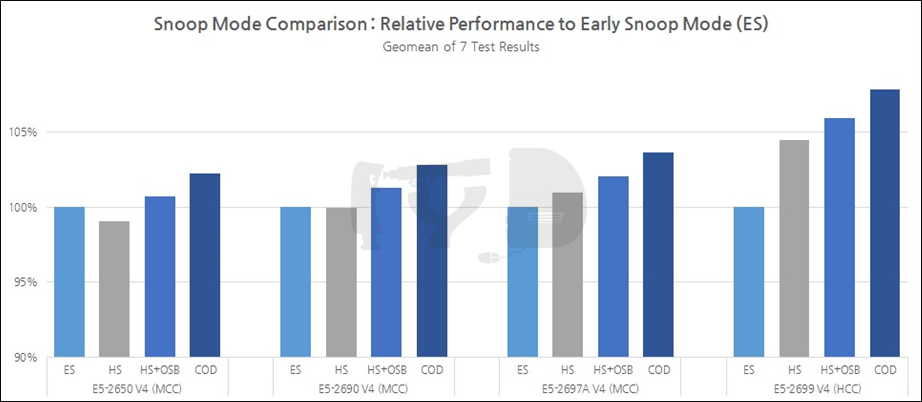
얼리 스눕과 홈 스눕의 장단점을 논하며, 코어 갯수가 늘어날수록 홈 스눕의 이점이 커진다는 취지로 설명한 바 있습니다. 개별 코어와 L3 캐시 사이의 레이턴시가 너무 변동성이 커지는 얼리 스눕과 달리 홈 스눕은 중앙집권적으로 이를 통제할 수 있기 때문인데요. 이 점을 반대로 해석하면 코어 갯수가 적을 경우 얼리 스눕이 더 유리할 수 있다는 것도 됩니다. (적은 코어끼리 최소한의 레이턴시로 스누핑을 하는 것이 중앙집권자를 거쳐 스누핑을 하는 것보다 빠르기 때문입니다.)
이를 정확히 보여주는 것이 위 그래프입니다. 홈 스눕의 얼리 스눕에 대한 상대성능은 거의 코어갯수에 정비례해 증가하는 양상을 보입니다. OSB는 홈 스눕의 개량형이기에 기본적으로 홈 스눕의 양상을 따라가며, COD 역시 '코어 갯수가 너무 많을 때의 문제 해결'을 위해 도입된 것이니만큼 코어 갯수가 늘어감에 따라 성능이 증가하는 것은 지극히 자연스럽습니다.
그렇다면, 위 네가지 모드 중 가장 좋은 성능을 보인 COD는 가장 좋은 선택일까요. 아래 그래프를 한번 봅시다.
사실 COD의 약점은 하나의 CPU를 두 개의 논리적 소켓처럼 해체해버리는 데 있습니다. 어찌 되었든 모든 코어가 작동 중이면 큰 문제가 없겠지만 '한쪽 링 도메인을 꺼 버릴 정도로' 워크로드가 가볍거나, 다른 링 도메인 소속의 메모리컨트롤러를 참조해야 할 경우 거의 '별도의 물리 소켓' 만큼이나 대역폭 하락을 겪게 되기 때문인데 위 그래프가 이 점을 정확히 보여주고 있습니다.
결국 COD는 '하이 리스크, 하이 리턴'인 셈입니다. 고도로 멀티스레드에 최적화되고, 멀티소켓에 최적화된 메모리 액세스가 행해지는 작업 하에서라면 최고의 성능 향상을 볼 수 있지만 그렇지 않은 상황이라면 성능의 기복이 큰 점이 문제가 됩니다. 이를 감안했을 때 가장 좋은 스눕 모드는 홈 스눕 + OSB으로 여겨집니다. 결국 기-승-전-브로드웰이군요.
9. 결과 분석 및 트리비아
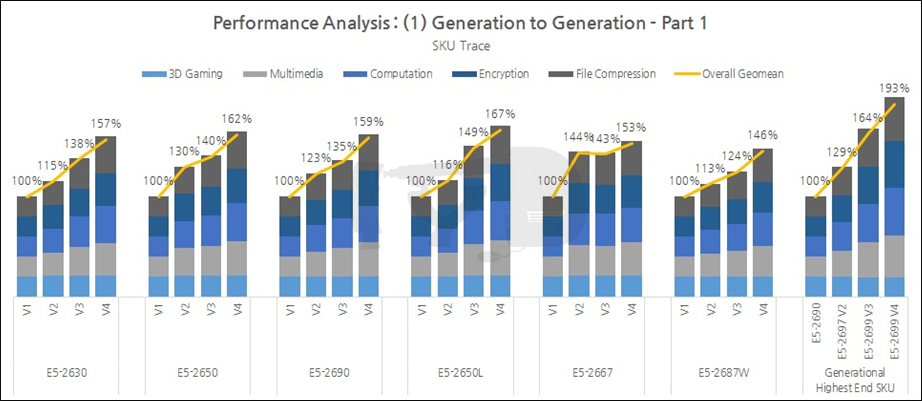
지금까지 살펴본 테스트 결과를 종합해 봅시다. 5개 벤치마크 도메인별 성능과, 이들의 기하평균값인 '총 성능 인덱스'를 아래 그래프에 나타내 보았습니다.
동일한 모델넘버끼리의 추적 비교 결과, 대체로 모든 SKU에 걸쳐 1~4세대간의 성능향상폭은 50~60%대에 큰 기복 없이 걸쳐 있는 것으로 나타났습니다. 이와 별개로 최상위 SKU간의 비교에서는 더욱 가파른 성능향상폭을 보여 E5-2690과 E5-2699 V4의 격차는 거의 2배에 달했는데, 세대간 최상위 SKU의 성능향상폭 역시 거의 선형적인 전개를 보여 적어도 서버 시장에서만큼은 인텔이 (데스크탑과 달리) 꾸준한 고성능화를 추구해 왔음이 드러났습니다. 이것 역시 경쟁이 있고 없고의 차이를 잘 보여 주는 예라 하겠습니다.
주목할만한 것은 2630들 사이의 성능관계인데요. HEDT과 '닮은꼴 스펙'을 갖는 해당 SKU의 특성상 이들끼리의 비교는 정확히 당대의 HEDT - 코어 i7 3960X, 4960X, 5960X, 그리고 곧 출시를 앞둔 6950X의 대리전으로 해석할 수 있습니다. 보시다시피 2630 V4는 V3보다 13% 더 높은 성능을 보여주고 있기에 i7 6950X 역시 5960X보다 그 만큼 높은 성능을 보일 것으로 예상해볼 수 있겠습니다.
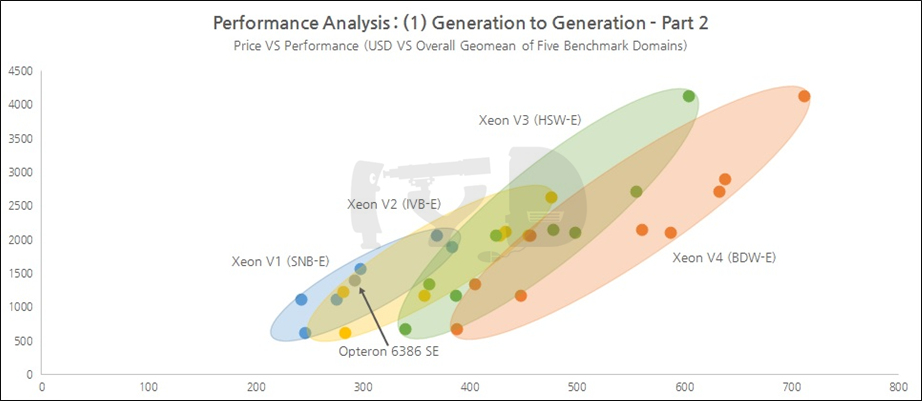
위 그래프는 앞에서 구한 총 성능 인덱스와 가격의 분포도입니다. 세대가 지날수록 제온 E5의 분포는 확연히 우편향되어가고 있습니다. 눈에 띄는 것은 옵테론 6386 SE의 위치인데, 비록 오늘날의 제온 E5와는 거리가 멀지만 옵테론이 현역이던 당시의 제온 E5 - 샌디브릿지-EP와는 정확히 한 클러스터에 속한 것을 볼 수 있습니다. 이것 역시, 당시의 옵테론은 실제로 제온 E5와 비교해 대등한 경쟁력이 있었음을 의미합니다. 비록 과거의 영광에 불과하나 데스크탑 시장에서는 이미 이때 FX가 저 깊은 곳으로 침몰하던 것을 생각하면, 확실히 데스크탑에서의 성능의 척도와 서버/워크스테이션에서의 척도가 다르다는 것을 실감하게 됩니다.
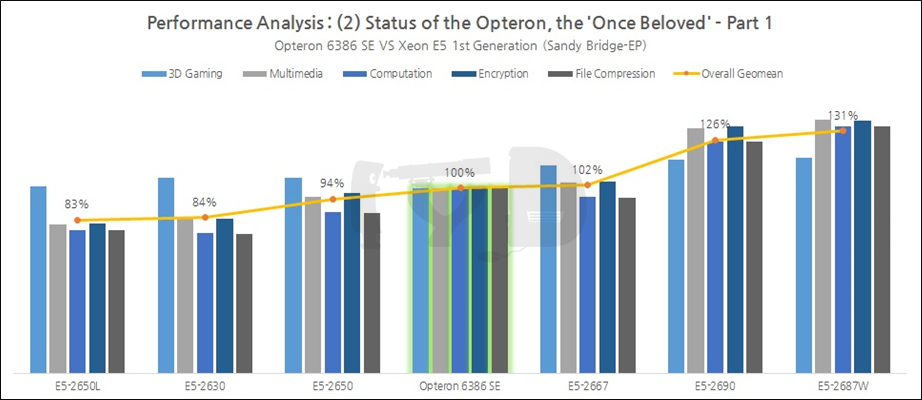
'한때 잘 나갔던' 옵테론을 좀 더 자세히 조명해 볼까요. 아래 그래프는 옵테론 6386 SE와 샌디브릿지-EP 기반 제온 E5 SKU들의 성능을 비교한 것입니다.
참고로 위 그래프는 총 성능 인덱스를 기준으로 좌우정렬된 것인데, 흥미롭게도 전체 1세대 제온 E5 라인업의 정 가운데에 옵테론 6386 SE가 자리잡고 있습니다. E5-2667과 2승 3패를 기록한 것을 생각하면 사실상 멀티스레드 성능이 중시되는 분야에서는 상위권에 속하는 셈이죠. 한때였을지언정 사랑받았던 것은 허명이 아니었음을 증명합니다.
그러나, 오늘날의 제온들과 비교하면 그저 참담할 따름입니다. 사실 파일드라이버 이후 AMD가 내놓은 x86 아키텍처들을 살펴보면 스팀롤러가 파일드라이버 대비 6.5%, 엑스카베이터가 스팀롤러 대비 8.6%의 IPC 향상폭을 보여 인텔이 샌디브릿지 -> 아이비브릿지(5.2%), 아이비브릿지 -> 하스웰(6.0%)에서 기록한 향상폭보다 오히려 더 큽니다. 그 말인즉, 서버 시장을 완전히 놓아버리지 않고 꾸준히 스팀롤러 기반의 옵테론, 엑스카베이터 기반의 옵테론을 출시했더라면 어느 정도 승산이 있었으리라 생각해봄직 하죠. 그러나 이런 분석은 너무 단편적으로 흘러가기 쉽습니다.
바로 AMD 스스로, 스팀롤러 기반의 유일한 데스크탑 프로세서인 카베리를 출시하며 그에 대한 해답을 준 바 있습니다. 당시 AMD는 IYD와의 인터뷰(링크)에서 스팀롤러 기반 FX나 옵테론을 출시할 계획이 없다고 못박았는데, 그 이유는 스팀롤러 아키텍처로 파일드라이버 수준의 작동속도를 달성하기 어렵기 때문이라고 했죠. 이듬해 엑스카베이터 기반의 APU '카리조'를 출시하면서는 이런 한계가 더욱 뚜렷해져 아예 데스크탑 시장에는 출시조차 되지 못했습니다. 저클럭으로 충분한 모바일용으로 공급되었을 따름입니다.
IPC는 작동 속도가 같아야만 의미가 있습니다. IPC가 아무리 올랐더라도 작동 속도가 대폭 떨어지면 의미가 없어지는 것이죠. 이미 스팀롤러 기반 FX / 옵테론을 출시하지 않기로 한 시점에 AMD 내부에서는 IPC x 작동 속도가 현행 파일드라이버 기반 FX / 옵테론을 넘어서지 못한다는 결론을 내린 뒤일 것입니다. 엑스카베이터의 경우도 마찬가지입니다. 또한 IPC와 클럭뿐만 아니라 제온의 성능향상이 코어 갯수 자체의 증가에 기인하기도 한다는 점을 고려할 때, 14nm에 접어든 인텔과 28nm에 머물러 있는 AMD가 동일 면적에 집적할 수 있는 코어의 수 자체에도 차이가 있을 수밖에 없습니다.
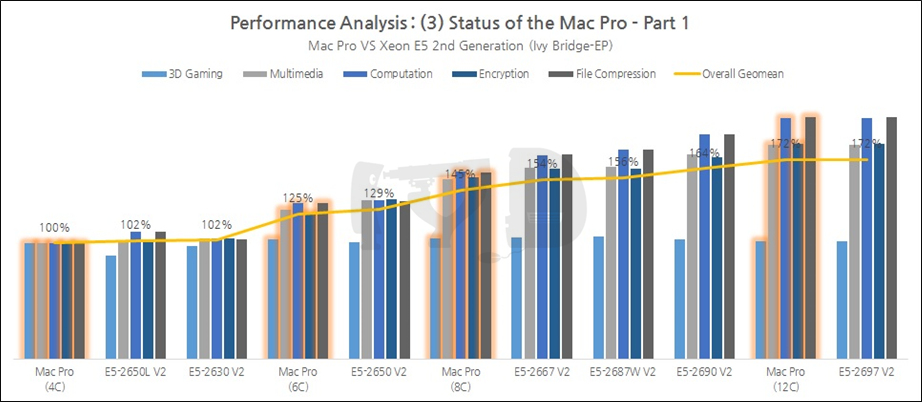
이번에는 조금 재미있는 비교를 해 봅시다. 애플의 최고 사양 워크스테이션 '맥 프로'에 탑재된 제온 SKU들과의 비교입니다. 맥 프로의 현 위치를 객관적으로 점검해보자는 취지입니다.
맥 프로 출시 당시 현역이던 제온 E5 V2와의 비교입니다. 최하위 4코어 트림은 예상했다시피 가장 낮은 성능을 보이고 있지만 10코어 SKU인 2650L V2, 6코어인 2630 V2와 거의 같은 성능을 보였단 점에서 오히려 선방이라고도 볼 수 있겠고, 상위 6코어 / 8코어 트림 역시 전체 라인업 중에서도 비교적 괜찮은 수준의 성능을 보여줍니다. 2697 V2를 사용한 12코어 맥 프로는 두말할것 없죠.
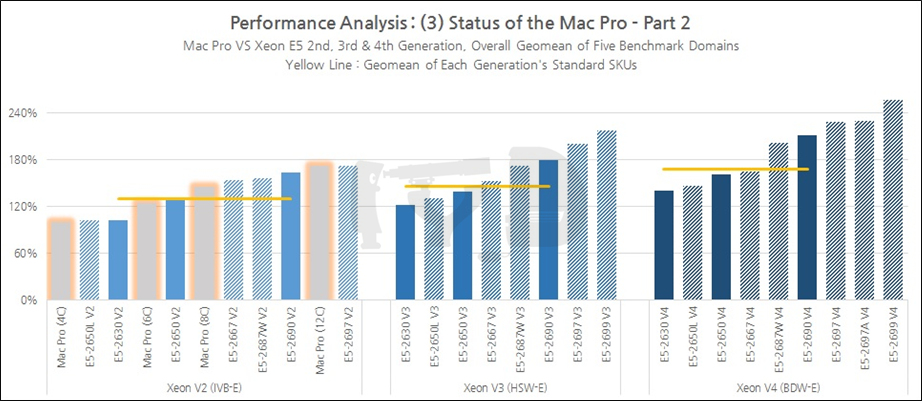
그러나 어디까지나 2013년을 기준으로 했을 때 얘깁니다. 지금은 2016년, 그 사이 제온은 두 번의 세대교체를 더 거쳤습니다. 과연 지금의 제온과 비교하더라도 맥 프로의 성능은 여전히 매력적일까요?
하스웰 세대까지만 하더라도 6코어 맥 프로는 E5-2630 V3과, 8코어 모델은 2650 V3과 대등한 성능을 보여 현역급으로 간주하기 충분했습니다. 12코어 트림 역시 2690 V3에 근접한 성능을 보였기에 비록 가격은 비쌀지언정(12코어 트림은 6499달러부터) 시대에 뒤처진다는 인상은 주지 않았습니다. 그러나 브로드웰 세대에 접어들어서는 얘기가 달라지는데요. 굳이 일대일 비교를 하지 않더라도 이젠 맥 프로가 한 차례 업데이트를 거쳐야 할 시점이라는 데 누구도 별반 이의를 제기하지 않을 것 같습니다. 새로운 맥 프로를 기대해 봅니다.
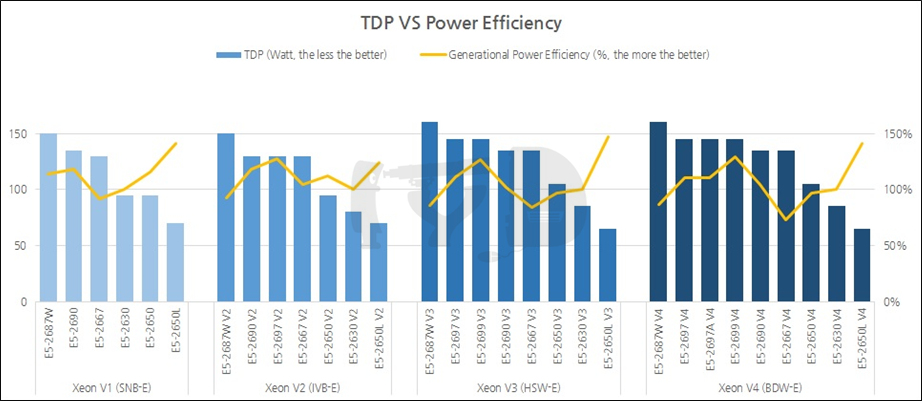
마지막으로 전력 효율에 관한 일반적인 상식을 뒤흔들어 봅시다. 아래 그래프에서 막대그래프로 나타낸 것은 각 SKU의 열설계전력(TDP; Thermal Design Power)을 나타내는데, 흔히 TDP가 낮을수록 전력 효율이 좋다고 합니다. 그러나 이 말은 반은 맞고 반은 틀렸습니다.
일반 데스크탑 CPU에서는 '낮은 TDP = 높은 전력 효율' 공식이 잘 맞습니다. 이들은 연산성능 편차가 크지 않기 때문입니다. 그러나 서버 시장에서는 이야기가 달라지는데, 개별 SKU의 코어 갯수부터가 폭넓게 달라지면서 연산성능 자체가 천차만별로 달라지기 때문입니다. 즉 어떤 SKU의 TDP가 높더라도, 그만큼 연산성능이 압도적으로 높아 어떤 작업을 더 빨리 처리할 수 있다면 특정 작업에 소요되는 '총 소비전력'은 오히려 TDP가 낮은 하위 SKU보다 적어질 수 있는 것입니다. 위 그래프에서 노란 꺾은선그래프로 나타내어진 것이 바로 '전력 효율'을 의미합니다.
저전력 특화 SKU인 E5-2650L들이 각 세대별로 가장 낮은 TDP와 가장 높은 전력 효율을 기록한 것은 모두의 상식에 부합합니다. 그러나 놀라운 건 TDP가 보통 한 세대 내에서 2위권으로 높은 편인 최상위 SKU들의 전력 효율이 2650L들 다음으로 높다는 것입니다.
일반적인 용도의 PC에서 전력 효율은 구매의사 결정에 그리 중요한 역할을 미치지 못합니다. PC 부품의 소비전력이 기껏 해야 수십W, 많아도 수백W 차이에 그치는데, 이것은 가정 내에서 사용되는 가전제품의 소비전력 스케일과 비교하더라도 대단히 낮은 편이기 때문입니다. 그렇지만 CPU를 여러 개 구동하는 서버나, 극단적으로 연산성능을 구축해야 하는 슈퍼컴퓨터에서는 전력 효율이 '총 소요비용'(TCO; Total Cost of Ownership)을 결정하는 중요한 요소가 되고, 따라서 전력 효율을 따지는 것이 중요합니다.
위 결과로부터 얻을 수 있는 교훈은, 빡센 서버를 구축해야 하거나 슈퍼컴퓨팅 클러스터를 도입해야 하는 기업이 '어설프게' 어중간한 TDP를 갖는 중간 모델을 선택하는 것은 엄청난 손해란 것입니다. 다소 예산을 더 들여서라도 당대의 최상위 SKU를 사거나, 혹은 그 돈으로 저전력 특화 SKU를 '더 많이' 사는 편이 장기적으로 이득이 됩니다. 지금까지 각종 벤치마크에서 약세를 보였던 2650L들을 깔보던 분이 계시다면, 그야말로 핵반전으로 다가올 내용입니다.
이 장을 마치기 전에, 개인적으로 생색 하나 내고 가겠습니다. 다섯 벤치마크 도메인의 성능 인덱스를 취합한 총 성능 인덱스를 보면 동일한 모델넘버의 두 SKU E5-2697 V4와 2697A V4의 성능은 결과적으로 매우 비슷해졌습니다. 코어 구성도, 작동 속도도 달랐던 이들은 각 벤치마크 도메인마다 때론 비슷한, 때론 사뭇 다른 성능을 보여 왔는데 결국 먼 길 돌아 제자리를 찾은 셈입니다. 여기서 강조하고 싶은 건, 실제로 인텔에서도 내부적으로 이와 비슷한 검증과정을 거쳐 해당 SKU에 2697이라는 동일한 모델넘버를 부여했으리라는 점입니다. (혹은 모델넘버를 먼저 붙이고, 테스트를 거쳐 가며 동일한 성능이 되는 작동속도를 찾은 것일지도 모르겠습니다.) 단편적으로나마 인텔의 '사내 벤치마크 시나리오'가 어떻게 구성되는지 이 글을 통해 엿볼 계기가 되었다고 자평하고 싶습니다.
10. 결론
지금까지 여러분은 인텔 제온의 역사와 현황, 주요 쟁점들을 A4용지 50여장 분량에 걸쳐 숨가쁘게 읽어 내려오셨습니다. 우선 수고하셨단 말을 드립니다. 이 글을 통해 저는 단순히 '제온이 이런 것이다'를 설명하는 것을 넘어, 장래에 제온을 구매할 가능성이 있는 예비 구매자들과 서버 관리자들, 프로페셔널들, 그리고 잘 모르지만 제온에 대한 막연한 동경을 가진 수많은 일반 유저들 - 폭넓은 스펙트럼에 걸쳐 있는 독자 여러분 모두에게, 제온이 구체적으로 어떤 사용자층을 겨냥했으며 각각을 대표하는 SKU에는 어떤 장단점이 있는지 등을 설명해 드리고 싶었습니다. 조금이라도 이 글이, 그런 면에서 도움이 되었을지 모르겠습니다. 만약 그랬다면 저로서는 큰 기쁨입니다.
모델넘버가 0으로 끝나는 일반 SKU들은 제온이라는 라인업 자체의 진화 양상과 비슷한 노선을 걷습니다. 한 세대가 경과하고, 인텔이 전세대보다 50% 늘어난 코어를 갖는 다이를 투입했다면 일반 SKU는 정확히 그 정도의 코어 갯수 상승을 겪게 됩니다. 인텔이 전세대보다 클럭을 200MHz 높였다면 일반 SKU들은 거의 대부분 이를 따라갑니다. 이들은 전형적인 '모범생' / '표준형' 들입니다. 서버용으로든 워크스테이션용으로든, 제온은 반드시 필요하되 구체적으로 어떤 세그먼트를 지향할지 모르겠다면 일반 SKU 중 예산이 허락하는 가장 비싼 것을 사면, 대개 만족스러운 성능을 보장합니다.
모델넘버가 7(또는 3)로 끝나는 친구들은 '프리퀀시 옵티마이즈드' 즉 고클럭 최적화 제품군입니다. 이 중에서도 세그먼트의 투톱인 2667과 2687W는 지향점이 조금 다른데, 2667이 오로지 고클럭만 추구하는 외곬수라면 2687W는 기본적으로 고클럭을 지향하되 당대의 '주류' (일반 SKU) 와 너무 멀어지지는 않는, 적절한 밀당을 구사하는 제품이라 할 수 있습니다. 근래 들어 최상위 다이의 코어 구성이 극도로 고도화되며 2687W 역시 차츰 데스크탑 CPU와는 큰 차이를 갖게 되는 추세입니다. 2687W V4는 14코어에 달합니다.
-L 접미사가 붙는 저전력 최적화 SKU들은 프리퀀시 옵티마이즈드와 정 반대의 대척점에 있는 이들입니다. 반도체의 고클럭화는 필연적으로 작동 전압의 상승과, 그 제곱에 비례하는 소비전력=발열의 상승을 수반하게 됩니다. 저전력을 추구하면서도 성능이 곤두박질치는 것을 막기 위해서는 작동 속도를 낮추는 반대급부로 코어 갯수를 늘려야 했고, 따라서 -L SKU들은 특히 2667과 정 반대의 설계철학을 지녔다고 볼 수 있습니다. 과거 제온에 사용되는 다이 자체가 코어 갯수가 그리 많지 않던 때에는 -L SKU의 성능이 아주 보잘것없는 수준이었지만, 하스웰 및 브로드웰 세대 들어 이들의 코어 갯수가 최대 12~14개로까지 증가하며 높은 전력효율로 멀티스레드 성능을 구사해야 하는 분야에 아주 좋은 솔루션이 되었습니다. 특히 앞 장 말미에서 TDP와는 별개의 '전력 효율' 개념을 짚어보며, 저전력 SKU들이 슈퍼컴퓨터에 사용될 경우 한정된 TCO 하에서 가장 좋은 연산성능을 뽑아낼 수 있는 솔루션이 될 수 있다는 점도 확인했습니다.
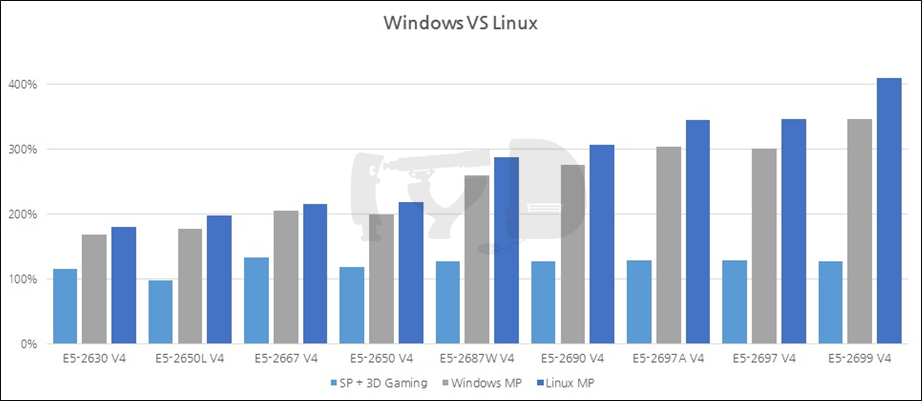
한편, 4장에서 수박 겉핥기식으로 제온 E5와 E7의 차이를 알아보았는데 사실 둘의 핵심적인 차이는 이들이 겨냥하는 '시장'에 있습니다. 제온 E5가 윈도우 기반의 워크스테이션, 리눅스 기반의 상대적 경량급 서버 시장을 지향한다면 E7은 정통 메인프레임을 지향한다는 차이가 있죠. 비록 E5로나마 리눅스에서의 성능을 심도 있게 살펴보는 것은, 비슷한 하드웨어 구성의 E7이 리눅스/유닉스 서버에서 보이는 성능에 대한 좋은 시뮬레이션이 될 수 있습니다. 특히 '윈도우에 대한' 리눅스 성능을 알아보는 것은 그런 맥락에서 더 의미있을 것입니다.
위 그래프가 말해주는 것은 두 가지입니다. 하나는 제온 E5가 그 자신의 타겟 시장층에서 발휘할 성능보다 E7이 자신의 타겟 시장층에서 발휘할 성능이 명백히 더 높다는 것, 다른 하나는 '여전히' 윈도우는 서버나 HPC용으로 그리 적합하지 않다는 것. 여기에는 OS 차원의 오버헤드, 메모리 관리 방식, 스레드 관리 방식 등 여러 원인이 영향을 주었겠지만 간단히 요약하자면 "왜 많은 HPC 어플리케이션들이 리눅스용으로 제작되는가" 에 대한 답이 아닐까 싶습니다.
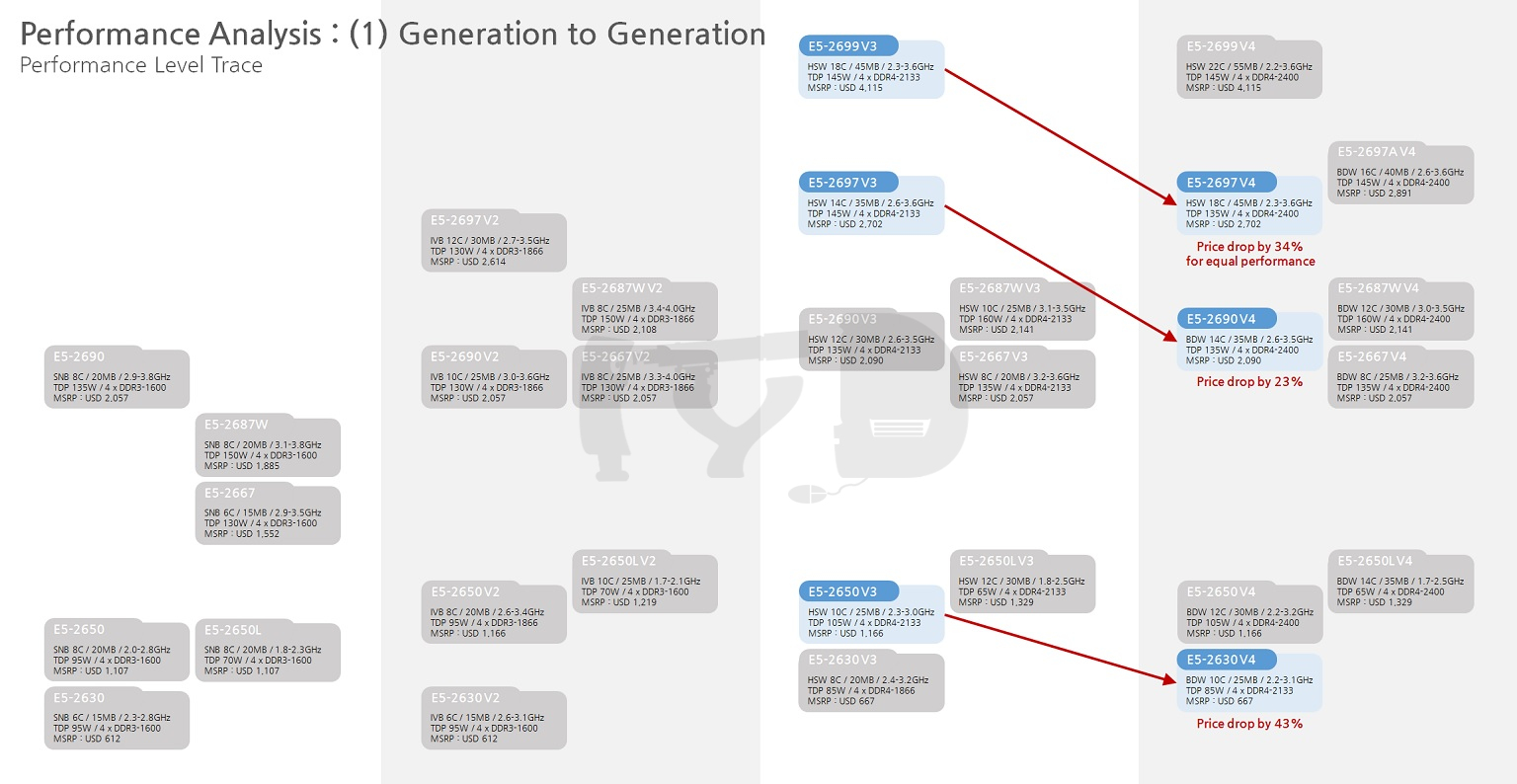
끝으로 제온 E5 V3에서 V4로의 세대교체가 갖는 의미를 살펴보며 대단원의 막을 내리도록 하겠습니다. 아래 그래프를 봅시다.
4115 달러나 하던 최상위 SKU, E5-2699 V3은 2.3GHz로 작동하는 18개의 코어를 가졌습니다. 이와 정확히 똑같은 사양을 갖춘 E5-2697 V4는 무려 34%나 저렴해진 2702 달러입니다. 뿐만 아닙니다. 14코어 / 2.6GHz의 E5-2697 V3도 정확히 똑같은 사양의 E5-2690 V4가 대체하면 23% 저렴해지죠. 10코어 / 2.3-3.0GHz의 E5-2650 V3은 10코어 / 2.2-3.1GHz로 거의 비슷한 사양의 E5-2630 V4으로 대체될 경우 무려 43% 저렴해집니다. 4000 달러 이상의 최상위 라인업부터 1000 달러 이하의 하위 라인업에 이르기까지, 거의 전방위적으로 브로드웰-EP는 가성비 패치를 끼얹었습니다.
확실한 것은, 지금까지 이 정도의 가성비 급등은 제온의 역사에선 찾아보기 힘든 사건이란 점입니다. 아이비브릿지 세대가 도래했을 때도, 하스웰 세대가 도래했을 때도 상술된 SKU들의 성능관계에 있어 후세대가 전세대를 뛰어넘은 적은 없습니다. 저는 이례적인 '가성비 폭탄'의 이유를, 역설적으로 인텔의 고속성장이 마감된 데서 찾아보려 합니다.
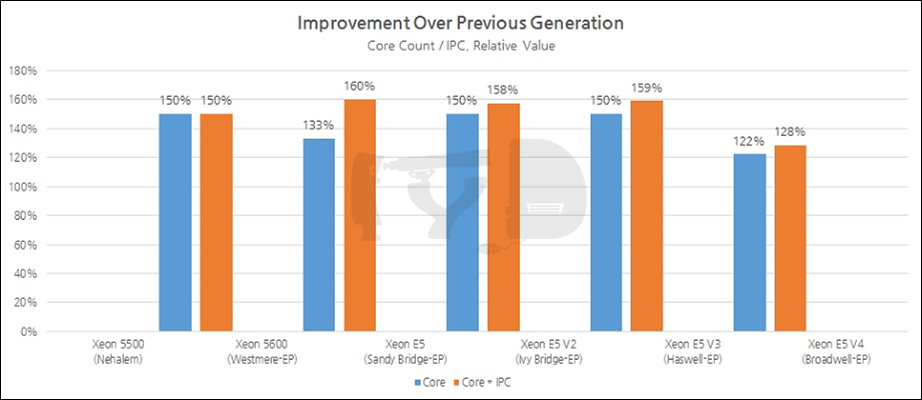
기술적인 측면에서만 보면 제온 E5 V4는 가장 불명예스러운 이름으로 기록될 위기에 처했다고 봐도 과언이 아닙니다. 네할렘 이래로 최상위 다이의 성능향상폭이 전세대 대비 1.5배를 달성하지 못한 첫 CPU이기 때문입니다. 제온 E5의 전신인 5500 시리즈의 네할렘(4C) -> 5600 시리즈의 웨스트미어-EP(6C) -> E5 샌디브릿지-EP(8C) -> E5 V2 아이비브릿지-EP(12C) -> E5 V3 하스웰-EP(18C)에 이르기까지 "1.5배 룰"이 지켜지지 않은 것은 단 한번, 웨스트미어-EP에서 샌디브릿지-EP로 이행할 때뿐이었습니다. 그나마 이때는 '톡'으로 큰 IPC 향상이 있었고, 코어당 면적 역시 크게 증가해 이뤄 사실상 1.5배 룰이 지켜진 것으로 간주되었지만 이번에는 빼박 '틱'에 불과하면서도 코어 갯수 증가폭은 22%에 그쳤습니다. 역대 최저폭의 성장입니다.
따라서 인텔로서는 브로드웰-EP가 상징하는 '위기의 징후'를 어떻게든 반전시킬 필요가 있었고, 그 결과 등장한 해결책이 '낙수효과에 의한 동반성장'이 아니었을까 싶습니다. 최상위 다이의 성능향상이 목표보다 낮아진 대신, 하위 SKU의 성능을 끌어올려 라인업 전체로는 오히려 전례없는 성능향상을 보여준다면 둔화된 성장 속도의 부정적 이미지를 단번에 상쇄할 수 있기 때문입니다. 진실은 인텔만이 알겠지만 어쨌든 이런저런 추측의 여지가 있다는 점은 리뷰어에게는 좋은 이야깃거리가 됩니다.
한 가지 바라는 게 있다면, 서버 시장에서 보여주는 적극적인 모습만큼이나 데스크탑 시장에서도 인텔의 '성의'가 느껴졌으면 한다는 겁니다. 이래서 경쟁이 중요한 것이겠지만요.
이것으로 기나긴 글을 마칩니다. 감사합니다.
페이스북, 트위터에서 IYD를 팔로우하시면 저희가 놀아드립니다!
http://facebook.com/insideyourdevice |
|||||





댓글 8
-
고라니
2016.05.07 20:03 [*.69.xxx.93]
엄청난 노력입니다... -
Sunggyu
2016.05.07 20:29 [*.233.xxx.195]
수고 하셨습니다. -
brainer
2016.05.07 20:39 [*.14.xxx.213]
와~엄청 나네요 22코어 44쓰레드 -
번개
2016.05.07 20:44 [*.52.xxx.224]
일단 분량을 보고 감탄, 내용을 보고 감탄. -
RAID0
2016.05.07 20:53 [*.49.xxx.163]
역시 클럭빨이 좋구만....주모 여기 오버클럭 한그릇~! -
번개
2016.05.07 21:02 [*.52.xxx.224]
ㅋㅋㅋㅋ -
Midnight
2016.05.07 21:33 [*.223.xxx.40]
수고하셨어요 -
퀄리티
2016.05.14 21:25 [*.161.xxx.86]
결국 일반인이 쓰는 게임용은 코어빨이 아닌 클럭빨..3770k 4.7오버로 3년동안 잘버텨준 내 콘퓨타 고마워.... 업글은 엄두도 못내지만... 내가.. 청소는 잘해줄께...